[SIGMOG'22] Sherman: A Write-Optimized Distributed B+Tree Index on Disaggregated Memory
Sherman:分离内存架构的写优化 B+ 索引结构。
关键技术:层级片上锁,两级版本结点结构,RDMA 命令组合。
名词解释
| 名词 | 解释 | 相关链接 |
|---|---|---|
| RDMA | Remote Direct Memory 远程直接内存访问,直接通过网络传输访问远端机器的内存,不需要远端机器的 CPU 参与 | https://blog.csdn.net/qq_21125183/article/details/80563463 |
| one-side words | 单边操作,指 RDMA 中不需要依赖接收方 CPU 的 RDMA 操作 | |
| Power of Two Choices | 一种选择策略,随机选择两个,在两个选择中选择一个较好的。 | https://www.nginx.com/blog/nginx-power-of-two-choices-load-balancing-algorithm/ |
| P<xx> latency | ||
| P<xx> 延迟 | i.e. P99 latency(P99 延迟),99%的请求延迟小于这个值 |
背景
- **分离内存的提出:**在计算资源和存储资源未分离的情况下,资源利用率较低。所以提出了在物理上将 **CPU 和内存分离为独立的组件,**实现内存资源的池化,有效提高资源利用率。
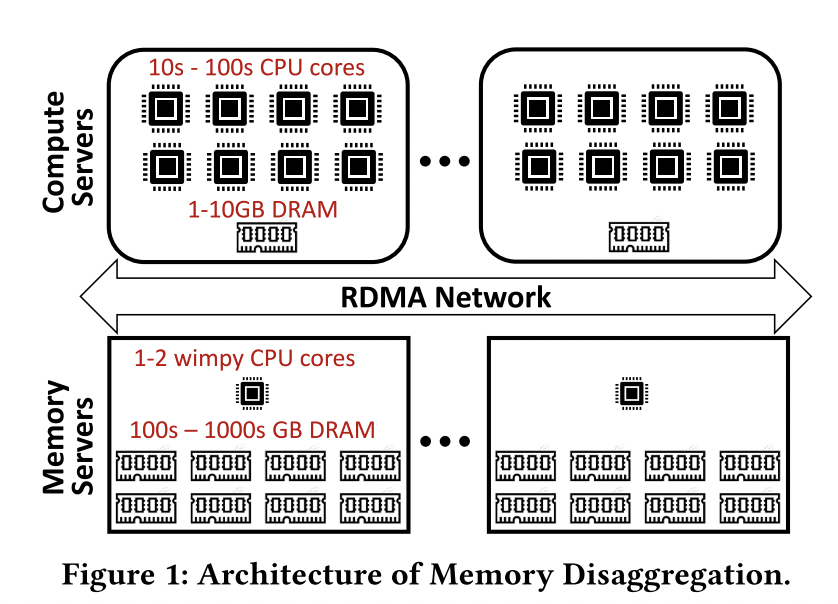
💡 如下图所示,本文讨论的分离内存架构分为
- 具有多核 CPU 和较少内存(可做本地缓存)的 Compute Servers (CSs)
- 具有少核 CPU(轻量级任务管理)和大内存的 Memory Servers (MSs)
- 提供数据交互的 Remote Direct Memory Access (RDMA) 网络
- 双面动词:RDMA_SEND 和 RDMA_RECV. 与 Linux 套接字一致,需要接收方预先接收;
- 单面动词:RDMA_READ, RDMA_WRITE, RDMA_ATOMIC (RDMA_FAA, RDMA_CAS),无需接收方 CPU 操作。
分离内存——索引结构现状
- 基于 RDMA 的树索引 —— 采用 RPC(Remote Procedure Call) 方式处理写操作,由于分离内存内存侧计算能力几乎为 0,故不适用。
💡 Cell, FaRM-Tree 例如。
- 采用 RDMA 的单侧方法进行索引的所有操作 —— 具有高读写性能,但在写场景,尤其是高争用场景低吞吐量、高延迟。
💡 FG, RDMA based B+ Tree 唯一仅采用单边操作来完成索引写的,故可以用在分离内存场景。该系统没有缓存处理。
写:用通过获取 RDMA 侧自旋锁(RDMA_CAS取锁,RDMA_FAA释放锁)后写的方式。
读:乐观并发控制,先通过 RDMA_READ 获取节点内容,然后计算 check_sum 校验节点一致性,不一致重试。
定制写操作在硬件中 —— 具有较高 TCO(Total Cost of Ownership),无法大规模应用到数据中心。

总体设计目标
实现在分离内存架构中具有普适性和高读写性能的 B+ 树索引结构。
现有索引结构设计(FG e.g.)的痛点
往返次数多:
- 单侧 RDMA 动词语义有限,需要多阶段往返(获取锁,读取,写入,解锁),延迟与往返成正比;
- 由于往返较多导致关键路径长,进而加剧争用降低并发性能。
获得写-写锁速度很慢,甚至崩溃:
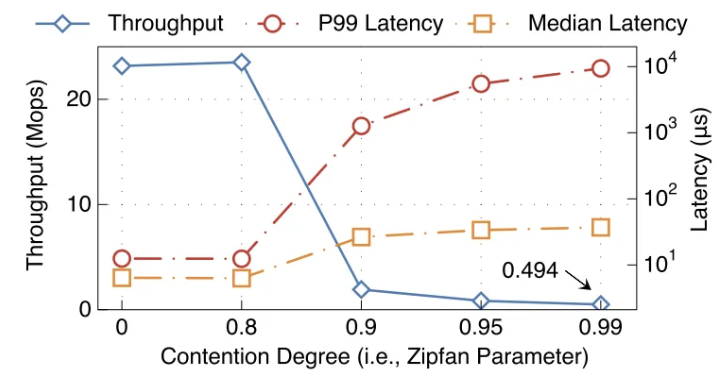
表现:跨7个 CSs 的154个线程获取/释放 10240 个位于MS中的锁表现如下图所示,争用率在 0.99 是十分常见的表现,在这个表现下,吞吐率变得很低,实际延迟变得很高。
原因分析:
在硬件层面,NICs 的并发控制:RDMA 原子命令需要两个 PCIe 事务。
RDMA NICs 并发控制:内部锁定方案,维护若干个存储桶,地址具有相同特定位的放入同一个存储桶,同一个存储桶的命令认为是相同的。在 RDMA_CAS 获取锁成功时,需要 PCIe 事务 1 将 CPU 内存中数据取到 NIC 中;在 RDMA_FAA 释放锁时,需要 PCIe 事务 2 将 NIC 中数据写回 CPU 内存中。
在软件层面,总是产生不必要的重试获取锁的操作。 RDMA 中的锁是通过网络访问的锁,相比共享内存下的锁设计其需要占用有限的 NIC 的吞吐量。(并且不能通过释放锁回调来通知客户端,因为 MSs 极其有限的 CPU 资源)
不公平性。没有考虑锁的公平性,导致某些客户端的请求饿死。
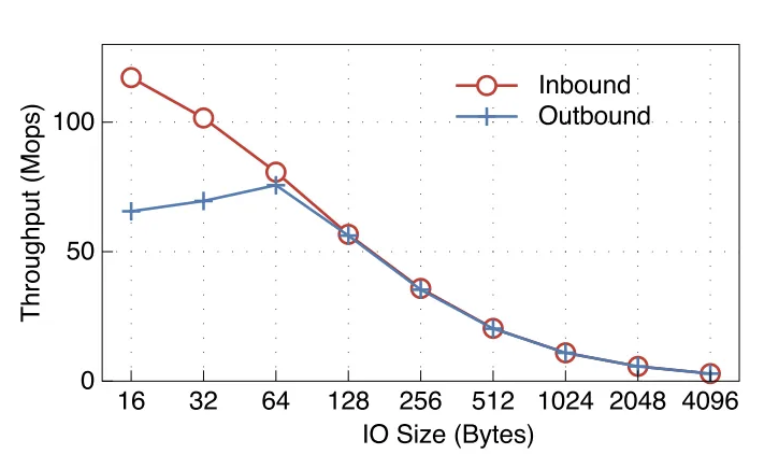
RDMA 倾向于小 IO,而索引数据结构的布局会导致严重的写放大现象触发大型 IO:
- 表现:当 RDMA 大小到达 256 字节时,NICs 的硬件带宽限制了吞吐量。
写放大现象的原因:
- B+ 树的节点内部是有序的,故当进行插入、删除操作时需要进行移位操作引起大范围 IO。
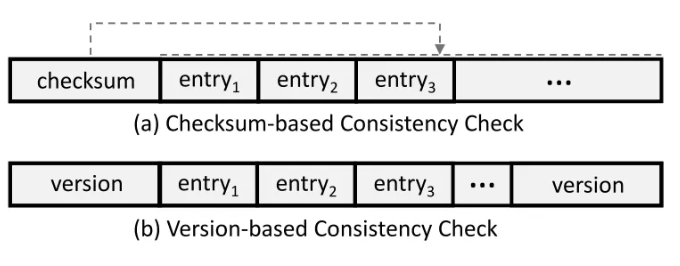
- 粗粒度的节点一致性检查。以下两种节点检查粒度是树节点,故在节点中的任意修改都要回写到整个节点中。
- 采用 checksum 做无锁读取,当校验和与计算出来的不一致时则认为数据无效;
- 采用基于版本的无锁读取,节点更新时先更新头版本号,更新完毕则更新尾版本号,当两级版本不一致则认为数据无效。
解决痛点的技术概括
主要思想:将 RDMA 硬件特性与 RDMA 友好软件机制进行结合。
- 为了减少往返行程,利用 RDMA 的顺序传递特性来合并 RDMA 命令。
- 为了加速并发访问,引入了分层锁,其中利用到了 RDMA 的片上存储器。
- 为了减轻写放大,定制了两级版本机制的 B+ 树数据结构。
实现细节
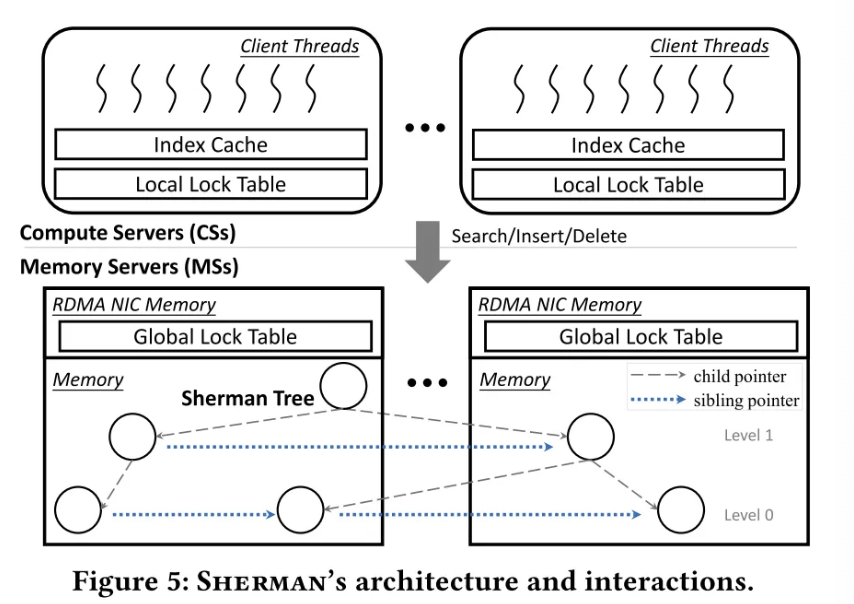
sherman 整体架构
如图所示,Sherman 由 Compute Servers, Memory Servers 两部分组成,Sherman 树的增删查改是由运行在 Compute Servers 的大量客户端线程来通过 RDMA 操作 MSs 完成的。
- 在 Memory Servers 中存储着类 B+ 树结构,其中指针节点由 64 位表示(16 位的 MS 标识符和 48 位对应 MS 的内存地址)。节点内部是未排序的。
- 并发控制:
- 写-写冲突:客户端线程做写操作时需要先获得位于自己 CS 中的本地排他锁,获得本地锁后再远程获得位于对应 MS 中 RDMA NIC 片上内存的全局锁。避免了 MS 侧的 PCIe 事务,减少了远程重试操作,提升了公平性。
- 读-写冲突:采用无锁搜索,采用两级版本机制检测读写冲突。该机制不同于传统的节点级版本,利用了入门级版本和节点级版本来减轻写放大。
- 缓存机制:
- 缓存节点:
- 叶子节点的父节点
- 根结点和根节点的子节点
- 缓存命中机制:先搜索 (a) 类节点,若 (a) 类节点命中,则直接到其指向的 MS 中拿数据;若未命中,则搜索 (b) 类节点,通过远程访问遍历其子节点搜索数据。
- 缓存组织形式:总是缓存 (b) 型节点;利用跳表组织 (a) 型节点,当跳表达到限制时,随机选择两个节点,将更少访问的节点逐出。
- 这种缓存模式,不会拿到脏数据的原因:
- 这种缓存只是减少间接访问到节点的次数,最终数据还是要直接到 MS 中拿的。故 B+ 节点格局(指节点树的形状)没变,数据就是对的。
- 当节点树的格局变了时,一个节点通过 <节点上下界, 层级(叶子为 0 )> 来表示节点树的格局,在 MS 中获取数据时检验这个格局,若检测到格局变化,则放弃数据、删除该缓存重新进行查找操作。
- 缓存节点:
- 内存管理:在每个 MS 中保留一个内存分配线程,该线程将自己内存划分为固定长度块;当客户端需要为 Sherman 分配内存时,先以循环方式选定一个 MS,再以 RPC 的方式请求内存(减少 MS 侧的计算开销);当回收内存时,只需要清除空闲位并释放就可。
层级锁
- 全局锁表:RDMA NIC 上提供部分片上存储器给上层应用,在这片存储区域进行操作避免了 NIC 的 PCIe 事务,吞吐量更大。在本文使用的 ConnectX-5 NIC 中提供了 256 KB 的容量,并且 RDMA 动词 masked compare and swap 可以操作 16 位,这样就能提供 131072 个锁,有着比较小的粒度。
- 本地锁表:
- 本地锁是控制着单一 CS 上的争用控制,在一个 CS 线程中需要获得一块区域的锁,必须先获取本地锁,获取锁之后在去远程请求全局锁。减少了单一 CS 中不同线程对同一块区域的远程锁请求的往返,减少了不必要的重试。
- 当锁释放时,CS 先在本地锁队列中查看是否有线程请求锁,如果有,则不对远程锁进行释放,而是将锁转移给该线程,减少了远程锁的申请。由于防止其他 CS 被饿死,这个转移次数需要限制。
- 每个 CS 的本地锁是关于所有 MSs 的本地锁,一个锁占用 8 个字节,总共占用每个 CS n * 8 * 131072 个字节空间。
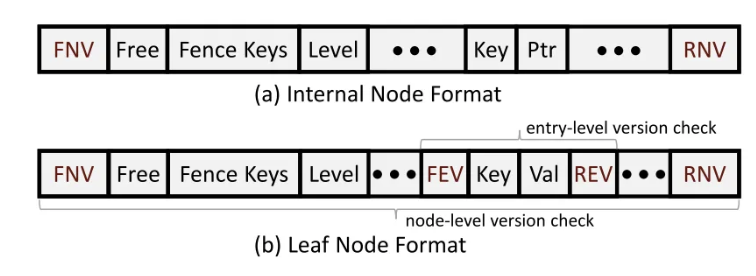
B+ 树结构
节点内部是不排序的,这样插入/删除就不必要做移位操作,从而减轻了写放大。未排序的叶节点导致:<1> 查找键时,需要遍历整个叶节点;<2> 拆分节点之前,需要对其进行排序。由于微秒级别的网络延迟,增加的开销很小。
采用两级版本做乐观锁。在 K-V 键值对中做第一级版本,当仅仅修改 Value 时只需要改入门级版本,减轻了写放大。在节点级做第二级版本,当节点拆分时,需要修改第二级版本。考虑到 K, V 均占 8 字节,第一级版本前后占 1 字节,采用两级版本多消耗的部分约占 1/17.
相关操作:
- 查找操作:首先客户端查找节点时,先将节点级的两个版本进行对比,若不匹配则重试;进而对 K-V 级别的两个版本进行匹配,若不匹配则重试。注意到两个版本匹配也是存在问题的,注意 K-V 级别的版本号只有 4 个比特位,若被修改了 次版本号也是匹配的,故这里限制前后两次 RDMA_READ 的时间在 内才有效。其中 单次写入操作的时间。
- 范围查询:对于范围查询,客户端并行发送多个 RDMA_READ 操作获取每个叶节点,然后和查找过程相同的方式检查叶节点的一致性。范围查询不提供原子性,故可能产生幻读问题。
- 删除操作:在没有叶节点合并时,只需将对应的 KEY 设为 NULL,并且将 K-V 级别版本号增加;触发合并时,需要额外增加使用节点级别版本。
RDMA 命令组合
由于 RDMA 在硬件上提供了排序属性:在可靠的连接队列对中,RDMA_WRITE 命令按照发送的顺序传输并且在 NIC 接收器顺序执行。因此可以在以下情景组合 RDMA_WRITE 命令来减少往返:
- 由于树节点和它的全局锁在同一个 MS 中,所以当回写完毕可即刻解锁,故 回写 和 释放锁 的命令可以组合在一起
- 当节点分裂时,若分裂出来的节点同在一个 MS 中,那么 回写新节点、回写老节点、释放老节点锁可以组合在一起
通用性
- Sharman 利用的 RDMA 的两个特性:
- RDMA 的命令有序性在 RDMA 规范中定义;
- 支持片上存储器的 ConnectX-5 NIC 已被广泛应用在数据中心。
- Sharman 技术可应用在其他类型的产品:
- 基于锁的索引都可以使用 层级锁 和 组合命令 来提高并发性能和减少往返
- 如果索引采用乐观锁设计,那么两级版本机制可以用来减轻写放大
评估
💡 Sharman 从以下几点评估:
- Sharman 在不同负载下的性能;以及 Sharman 的不同技术对整体性能做出的贡献;
- Sharman 的客户端的伸缩性;
- Sharman 的内部参数对性能的影响(如键大小,缓存大小等)
- 分层锁表的表现。
安装
硬件平台
由于分离内存硬件不可用,采用一组现有服务器,通过限制对 CPU 和内存的使用来模拟 MSs 和 CSs。集群由 8 台服务器构成,每台服务器配备 128 GB DRAM 和共 24核 CPU。1 台 100Gbps Mellanox ConnectX-5NIC。这些服务器通过 Mellanox MSB7790ES2F 交换机连接。将每台服务器模拟为一个 MS 和一个 CS。每个 MS 拥有 64 GB DRAM 和 2 个 CPU 内核,每个 CS 拥有 1 GB DRAM 和 22 个 CPU 内核。实验采用 8 个 MSs 和 8 个 CSs 进行。每个 CS 拥有 500 MB 索引缓存并启动 22 个客户端线程。对于每个实验,将填充 80% 可容纳 10 亿个条目的树。
对比系统 —— FG+
由于 FG 唯一支持分离内存的分布式 B+ 树,由于 FG 不是开源的,需要从头实现它,为了公平比较,对其进行了必要的优化,称其 FG+,经评估,FG 的性能高于 FG 论文中报道的性能:
- 对远程索引进行缓存
- 采用 RDMA_WRITE 释放锁而不是采用代价较高的 RDMA_FAA。
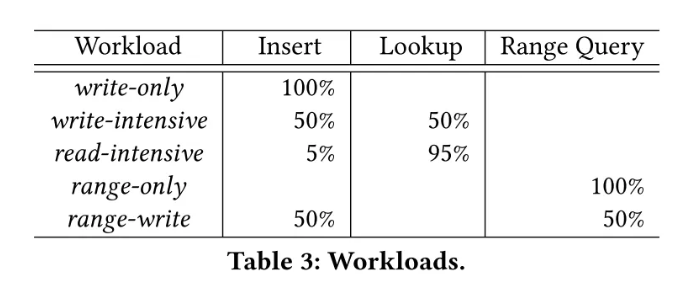
工作负载 —— YCSB
工作负载采用 5 种类型评测,仅写、写密集、读密集、仅范围查询、仅范围查询和写,比例如下表:
评估结论
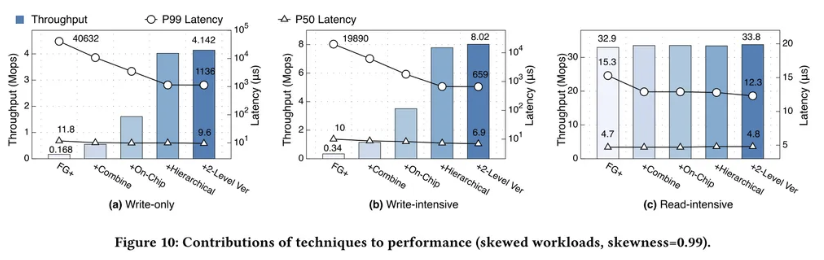
偏斜(高争用)负载下:
如下图所示,在仅写和写密集型工作负载中,Sherman 吞吐量比 FG+ 高得多,延迟也低得多:
- 仅写工作负载中:
- 吞吐量高于 FG+(24.7×)
- P99 延迟低于 FG+(35.8×),P50 延迟低于 FG+(1.2×)
- 写密集工作负载中:
- 吞吐量高于 FG+(23.6×)
- P99 延迟低于 FG+(30.2×),P50 延迟低于 FG+(1.4×)
Sherman 中的几个关键技术都有助于写入效率,以写密集型为例:
【命令组合】将吞吐量提高了 3.37 倍,并将 P50/P99 延迟降低了 1.14/3.18 倍
—— 归因于该技术为每个操作至少节省一个往返行程(进而缩短关键路径,降低冲突可能性)。
【片上内存锁】将吞吐量提高了 3.06 倍,并将 P99 延迟降低了 3.48 倍
—— 归因于该技术避免了 MS 端锁操作的 PCIe 事务,使得 RDMA 原子动词有了极高的吞吐量。由于没有事务在关键路径,冲突请求排队时间更短,P99 延迟更低。
【层级锁】将吞吐量提高了 2.22 倍,并将 P50/P99 延迟降低了 1.12/2.68 倍
—— 归因于该技术
- 获取远程锁之前先获取本地锁,避免了来自相同的 CS 的不必要的 RDMA_CAS 重试,减少了 RDMA NICs 有限的 IOPS 的消耗
- 每个 CS 中的本地锁通过维护等待队列保证先到先得得公平性,降低了尾部延迟
- 远程锁在本地的移交机制能节省一次往返
【两级版本机制】并没有带来可观的吞吐量改善 (3%)
—— 归因于目前主要瓶颈来自于并发冲突,而不是 RDMA IOPS。
P50 延迟减少 400ns(7.2us → 6.9us)
—— 较小的 RDMA_WRITE IO 大小在 CS 侧、MS 侧都有较短的 PCIe DMA 时间
Sherman 在读密集型工作负载中并没有很大的性能改进,因为技术改进针对提高写性能。
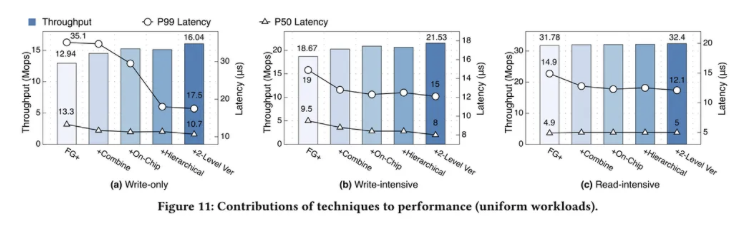
常规负载下:如下图所示,
对于吞吐量,Sherman 在仅写和写密集型工作负载吞吐量是 FG+ 的 1.24/1.15 倍。
—— 主要归因于命令组合和两级版本。
- 命令组合节省了往返,使得每个客户端线程可以执行更多的操作。
- 两级版本将 IO 大小从节点级别降到了 K-V 级别,发挥了 RDMA 极高的小 IO 速率特点。
—— HOCL 为高争用场景设计,因此不会增加常规负载下的吞吐量。
对于延迟,Sherman 在仅写和写密集型分别减少了 1.24/2.01× 和1.19/1.27× 的 P50/P99 延迟
—— 主要归因于命令组合和 HOCL。
- 命令组合节省了往返,降低延迟。
- HOCL 节省了 MS 端的 PCIe 事务,减少关键路径(直接减少延迟),并提高了锁的公平性(降低尾部延迟)
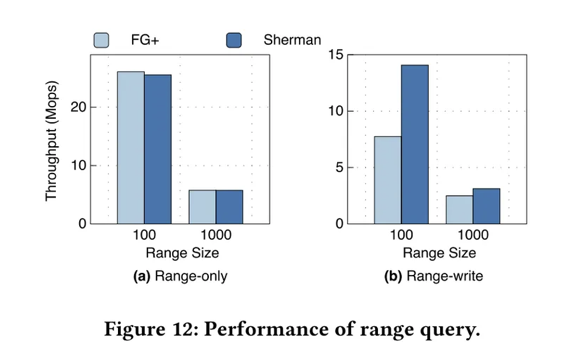
范围查询性能
通过使用仅范围和范围写入工作负载评估查询性能。
仅范围查询下:
当范围大小 ≤ 100 时,FG+ 的表现优于 Sherman 2%
—— 归因于 Sherman 中目标叶节点未占满时是未排序的,导致了不必要的读取。
随着范围大小的增长(即 1000),Sherman 和 FG+ 吞吐量下降并且几乎相同
—— 网络带宽成为瓶颈
当一半的客户端发起插入操作,一半的客户端范围查询操作:
Sherman 表现比 FG+ 高 1.82 倍
—— Sherman 的写操作节省了网络资源
- HOCL 机制减少了 RDMA Message 的数量
- 两级版本机制减小了 RDMA_WRITE IO 大小
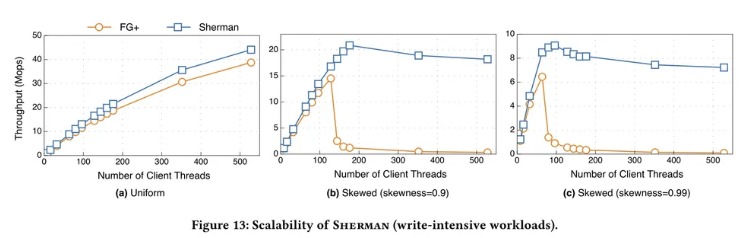
伸缩性能
由于 CSs 的内核有限,故采用 Boost 库中的协程来作为客户端线程。
如 a 图所示,在常规负载下,FG+ 和 Sherman 都具有良好的可伸缩性。在 528 个客户端线程的情况下,Sherman 实现 44 Mops 的吞吐量(1.14倍于 FG+)
—— 归因于两级版本机制:小粒度写回节点,节省了 RDMA 带宽
如 b, c 图所示,在偏斜负载下,较高的争用度导致较低的峰值吞吐量。
- 在 0.9 的偏斜度到达 21 Mops 峰值吞吐量,比 FG 高 1.44 倍。
- 在 0.99 的偏斜度下到达 9 Mops 峰值吞吐量,比 FG 高 1.4 倍。
—— 归因于争用越严重,并发写操作被阻塞的可能性越大从而降低了峰值吞吐量。
在高争用场景,当添加更多线程时,Sherman 可以提供可持续性的吞吐量,而 FG+ 性能崩溃。
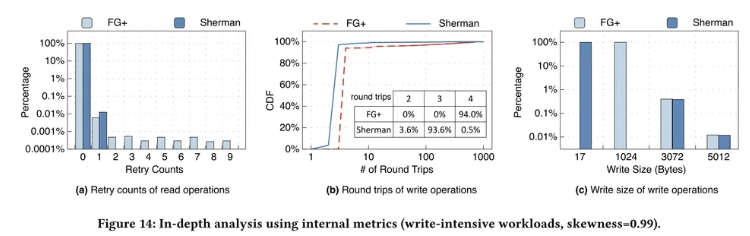
具体指标分析
对内部指标的统计数据进行分析:读取重试次数、往返次数、写入大小。
我们选择偏斜访问模式(偏斜度 0.99)的写密集型工作负载。
读取重试次数:
对于 FG+ 和 Sherman,查找操作的 99.98% 不需要重试。
—— 归因于 PCIe 链接保证了一定的原子性:PCIe 读取事务在先前的 PCIe 写入事务之后是严格排序的
FG+ 经历了几次(如 9 次)的读取重试
—— 归因于 FG+ 没有采用两级版本机制,导致较大的 RDMA IO 大小和 MS 侧较长的时长,增大了查找操作获取不一致的树节点的可能性
往返次数
FG+ 的 94% 的写操作达到 4 个往返,而 Sherman 93.6% 的写操作只有 3 个往返。
—— 归因于命令组合技术来合并写回和释放锁。
Sherman 中有 3.6% 的写操作只有 2 个往返。
—— 归因于锁在本地 CS 的切换机制机会性地节省 1 个往返。
FG+ 后 99% 达到了 453 次重试 —— FG+ 的尾部延迟很高。相反 Sherman 只有 11.
—— 归因于层级锁避免了大规模的锁定重试并提供了公平性。
写入大小
由于我们使用具有强局部访问特性的偏斜工作负载,因此只有 0.4% 的写入操作触发节点分裂从而导致大于 1KB 的写入。
对于没有节点拆分的写操作,Sherman 只需要写回 17 字节消除了写放大。
—— 归因于两级版本机制,写入 KV 键值对(16 Bytes + 1 Bytes 版本)而无需写回整个节点
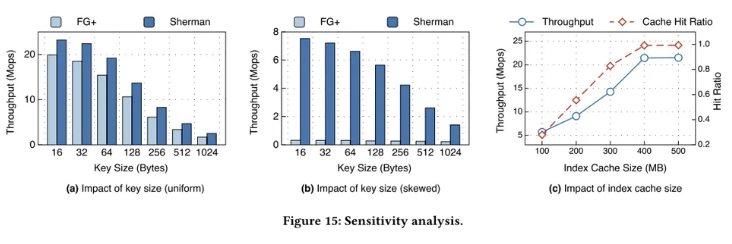
影响因素分析
Key 大小:随着 Key 增大,每个索引操作消耗更多的网络带宽,吞吐量都有所下降。
在常规负载下,随着 Key 大小从 16B 到 1KB,Sherman 相对于 FG+ 优势从 1.17x → 1.47x
—— 归因于 Sherman 的两级版本可以为更大的树节点节省更多的带宽
在偏斜负载下,由于 FG+ 在高争用场景极差的性能,导致其吞吐量未受 Key 大小影响。尽管在 Key 大小为 1KB 时,Sherman 的性能仍然比 FG+ 高 1.4 倍。
缓存大小:15c 所示,随着缓存索引容量的增长,Sherman 的性能和缓存命中率都提高了。对于大型数据集 (即10亿条目),400MB 索引缓存可以使缓存命中率接近 98%
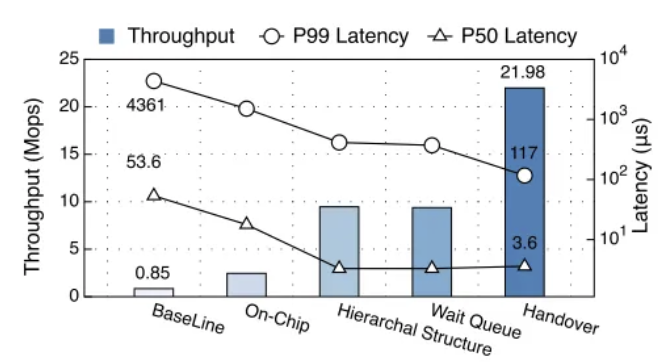
层级片上锁评估
启动跨 8 个 CSs 的 176 个线程来获取/释放存储在 MS 中 10240 个锁。采用 0.99 偏斜度的偏斜访问模式。
将锁放入片上存储器 → 吞吐量提高 2.89x,P50/P99 延迟降低 3.01/2.88x
—— 片上存储器消除了 RDMA_CAS 的 PCIe 事务,使得 NIC 处理数据更有效,缩短了冲突命令排队时间
在 CS 侧引入本地锁表并进一步形成分层结构 → 吞吐量提高 3.85x,P50/P99 延迟获得了 5.39/3.65x
—— 本地锁表避免了同一 CS 的远程锁请求
等待队列 → P99 延迟:414u s→ 372us
—— 等待队列提供了公平性,减少尾部延迟
等待队列的锁切换机制 → 吞吐量提高了 2.34 倍,减少了 3.19 倍的 P99 延迟
—— 本地将远程锁切换,避免远程锁获取,加速了锁的获取