f2fs 是怎么闪存友好的
本文探讨了问题:为什么 FLASH 在 FTL 层做了类似日志结构的写入方式,F2FS 还要在逻辑层做 LFS 还能够闪存友好?
闪存的 FTL 层
闪存 有如下几种特性:
- 先擦后写
- 擦写单位不一致,擦除单位是块(64 页或更多),写入单位是页(4KB-16KB)
- 每个芯片都是有写入次数寿命的(几万到几十万次不等)
FTL(Flash Translation Layer)为了提供向上统一的寻址接口,屏蔽了底层异地更新的事实
- 异地更新。即写入/更新页时需要新分配页写入。这样能够实现基本的芯片负载均衡以及解决了先擦后写且擦写单位不一致的现象。
- 地址映射。由于异地更新,如果需要向上提供统一寻址接口,所以逻辑地址不变,物理地址改变。
- 垃圾回收。由于异地更新,所以以前的页标记为无效,所以需要进行垃圾回收,而垃圾回收和擦除单位一致(块),所以需要迁移块内的有效页到新的位置。
- 坏块管理。屏蔽写入寿命完结的块。
可以看到 FTL 是无法感知上层应用页的冷热信息的,会导致如下现象。
|冷 冷 冷 热 冷 热 冷 ...|
热数据会很快被修改,原处会置为无效
| 冷 冷 冷 * 冷 * 冷 ... |
当无效页过多时会触发 GC,所有的冷页都要被迁移,这部分的迁移影响着 FLASH 的性能。
F2FS 的 LFS 基调
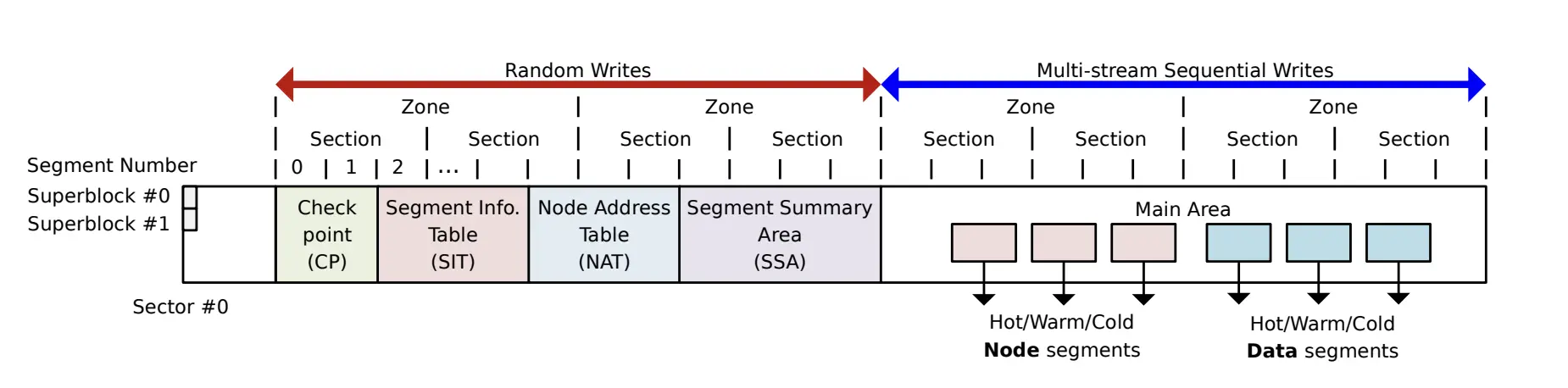
F2FS 基于 LFS(Log File System)设计,LFS 即异地更新的文件系统,为了避免 LFS 的 Wandering Tree (即更新块 -> 更新上级块指针 -> 更新上级上级块指针 -> ...)滚雪球效应,F2FS 在文件系统元数据区域设置了 NAT(nid -> addr) 区域,在 node 块中只存下级 node 的 nid 而不是 node 块的地址,这样只需要更新 NAT nid 对应的 addr 即可,从而阻止了 Wandering Tree 的问题。
那么回到问题:为什么 FLASH 在 FTL 层做了类似日志结构的写入方式,F2FS 还要在逻辑层做 LFS 还能够闪存友好?
其实并不是 LFS 做到闪存友好,而是多日志头做到的闪存友好。如下图所示,MAIN 区域的内容被分做了六块区域 HOT/WARM/COLD NODE/DATA。六块区域且隐式地将数据的冷热信息传递给了 FTL 层。具体来说,六个日志头在写页时能够做到以下情况:
冷区域持续不变 |冷 冷 冷 冷 冷 ...|
热区域会常改变,但只在上层标记无效,对于 FTL 层还是有效数据 |热 热 热 热 热 ...|
|热(逻辑无效) 热(逻辑无效) 热(逻辑无效) 热(逻辑无效) 热(逻辑无效) ...| |热 热 热 热 热 ...|
当逻辑做 GC 时,意味着原逻辑地址可写,在下次有新数据时会改动
|热(逻辑无效) 热(逻辑无效) 热(逻辑无效) 热(逻辑无效) 热(逻辑无效) ...|
=> |热(更改,物理无效)热(更改,物理无效)热(更改,物理无效)热(更改,物理无效)热(更改,物理无效)...|
|热 热 热 热 热 ...|
当物理做 GC 时,热页集中在一个块被修改,回收时迁移的数据就少了。
|热(更改,物理无效)热(更改,物理无效)热(更改,物理无效)热(更改,物理无效)热(更改,物理无效)...| => 都是物理无效的,不需要进行迁移。
可以看到,f2fs 的 LFS 和其他 FS 在更改一个页时,都是一次页的写入(还有隐式块的擦除),这方面并没有增加额外开销,但是让物理 GC 大幅度地减少了数据迁移(因为一个冷页可能会反反复复被迁移)。但还是会有额外的开销,即 F2FS 的逻辑 GC 需要有额外的搬迁,但只要软件设计时冷热分区合理,这部分的开销相比物理 GC 会小很多。