

计算机组成原理复习
本文为计算机组成原理笔记 📒,供个人复习使用。
参考教材:大萝卜 谭志虎《计算机组成原理》
数据表示
进制转换:十进制转 N 进制,整数部分除基取余,小数部分乘基取整。
求补手算:最右边的 1 左边的位数取反。
双符号位补码:00 表示正数,11 表示负数。出现 01 表示上溢,10 表示下溢
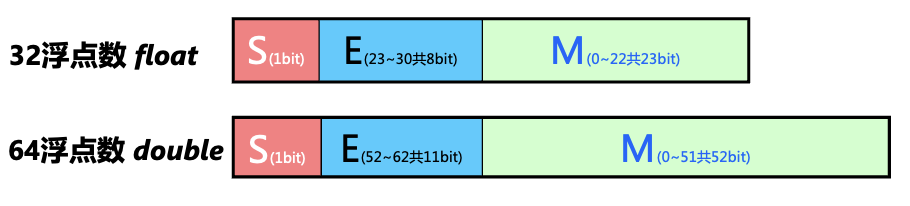
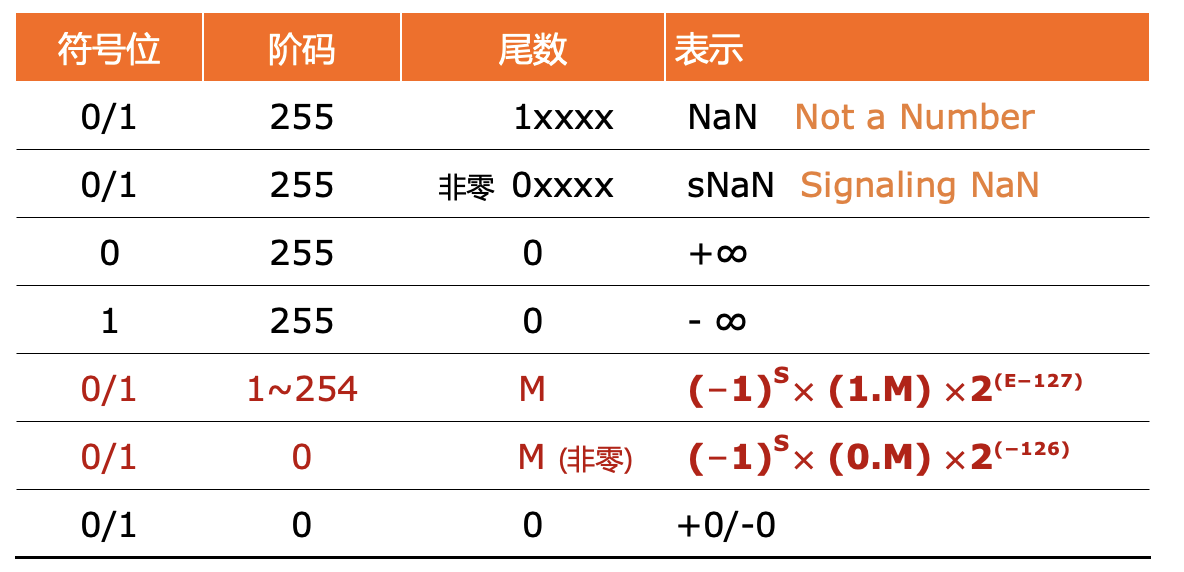
IEEE 754:
国标码 = 区位码 + 0x2020(20H 的控制字符继续沿用)
汉字机内码 = 区位码 + 0xA0A0 ,MSB = 1
94 * 94 矩阵区位码(行---区,列---位)
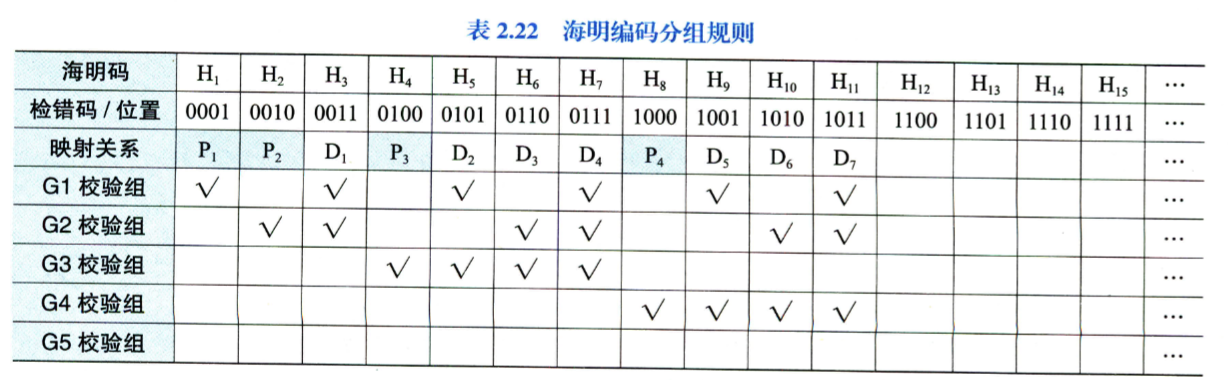
海明码:第 位是校验位 P,校验组 G 是对 P 和 P 所校验的数据位的异或。其中检错码是表示第几位海明码出错(即海明码从 1 起编号的原因)
扩展海明码:增加一个总奇偶校验位,可以区分是 1 位错还是 2 位错。
运算方法与运算器
加减法
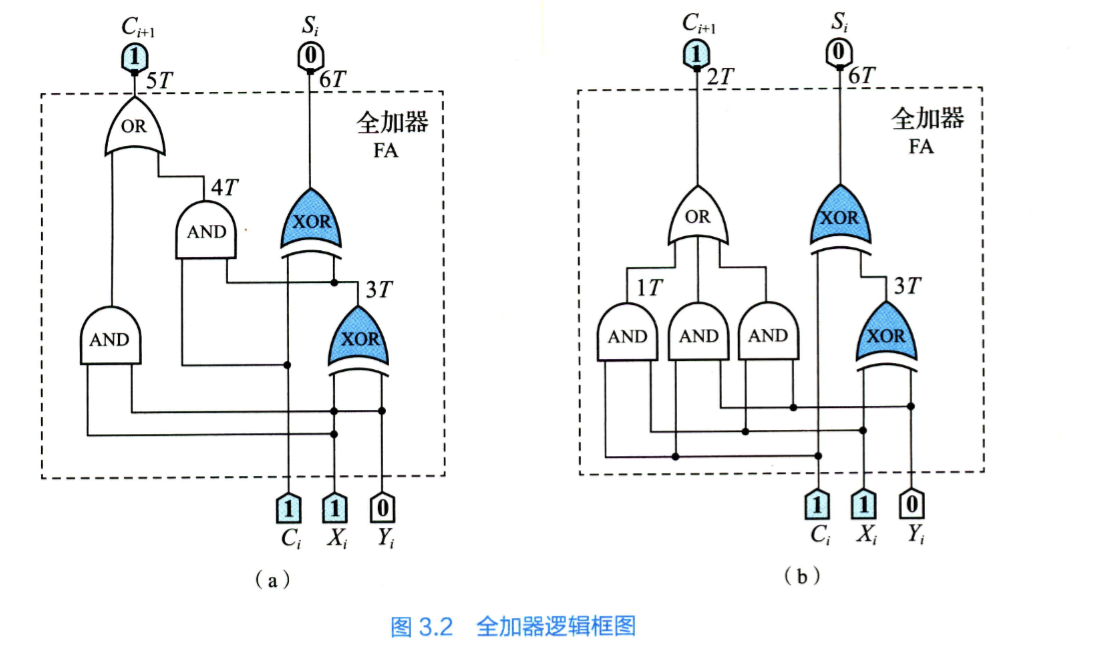
1 位全加器
溢出检测:
- ,符号位进位,数据位进位
- 双符号判溢出
- “正正得负,负负得正”
多位串行加法器
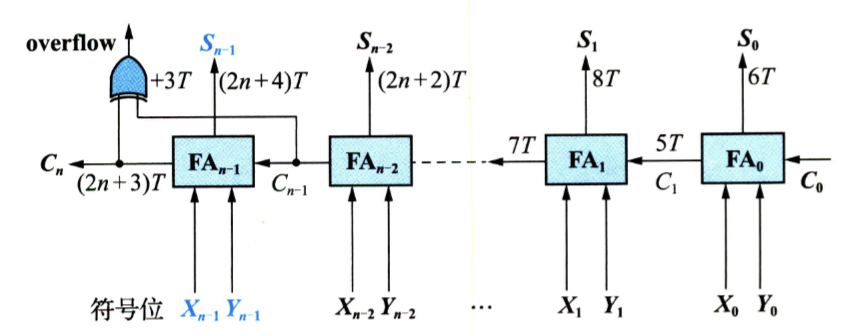
需要 3 T 得到所有 ,之后每隔 2 T (⬆️ 结合全加器图)能得到一个进位信号,得到进位信号后再 3 T 能得到本位和。
可控加减法电路
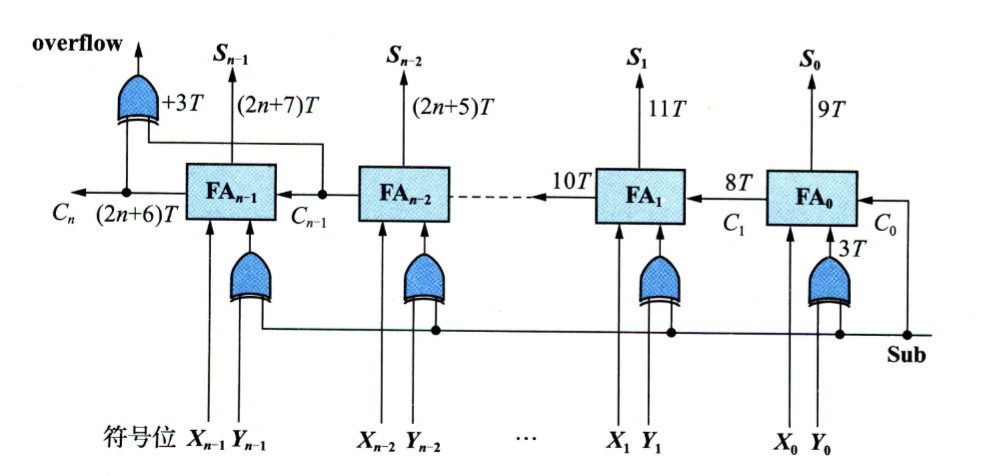
异或 SUB 则是为减号则取反,将 SUB 信号作为最后的加 1。相对 ⬆️ 多了 3 T 异或时延。
先行进位加法器
结合下图理解,先算进位生成函数 ,当两个都为 1 的时候产生进位源头。
再算进位传递函数 ,当有只有 1 个为 1 的时候会将之前的传递下去。
故 . 当前位值为
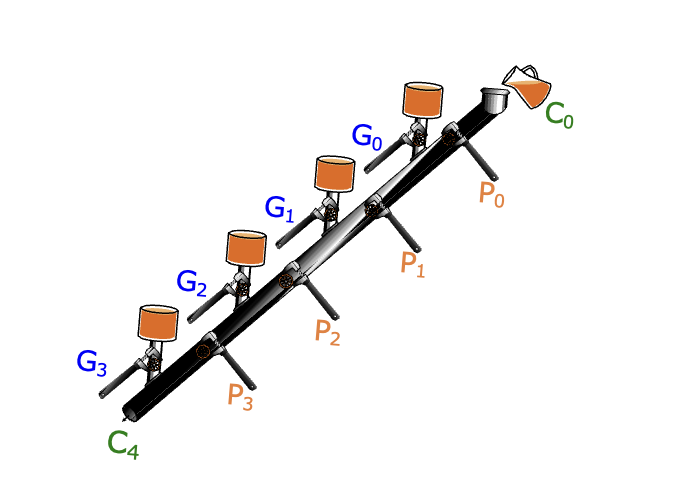
所谓并行,即通过这个递推式得到迭代形式同时得到所有的 ,进而同时计算本位。
迭代形式:
这些进位信号,如果用多输入与或门,只需要两级门延迟,而不需要依赖之前的进位信号,即减小了时延。
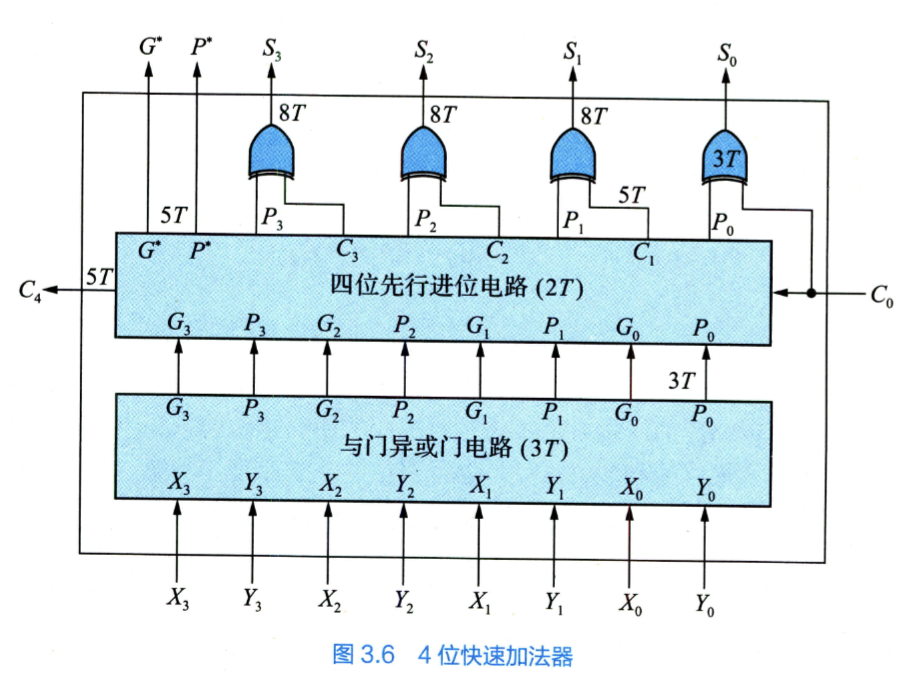
其中
为成组进位传递函数,用于多级先行进位系统。
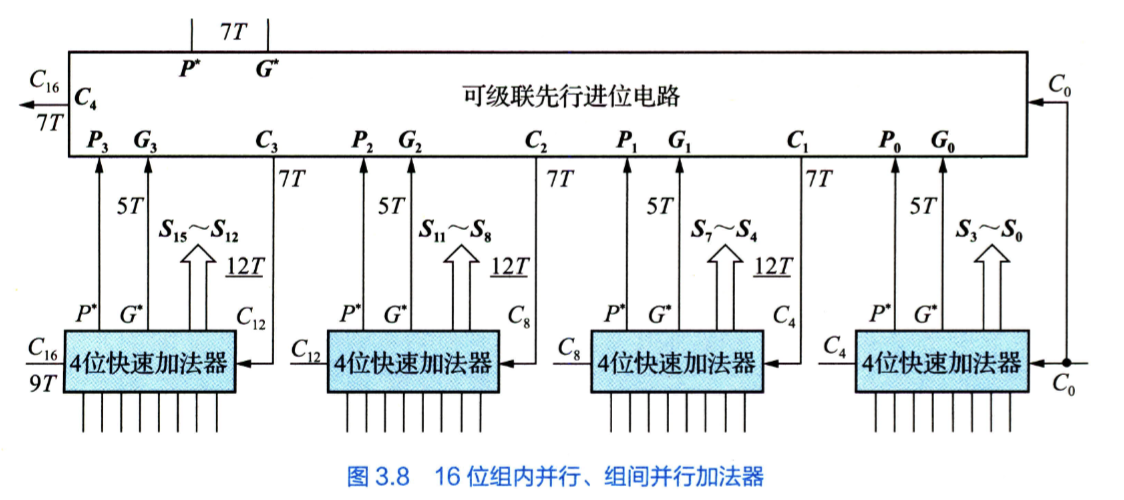
总结:生成 P、G 需要与门异或门电路 3 T,生成 P*,G*以及各进位信号需要 2T(当前置条件满足),生成本位和数需要 3 T。
定点乘法
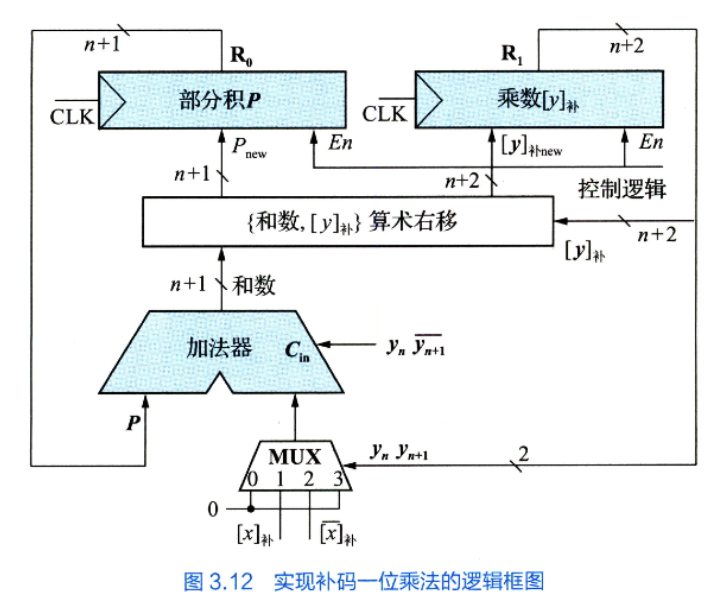
补码一位乘法(Booth 算法)
证明略。
核心逻辑:
实例体会:

存储器
存储器扩展
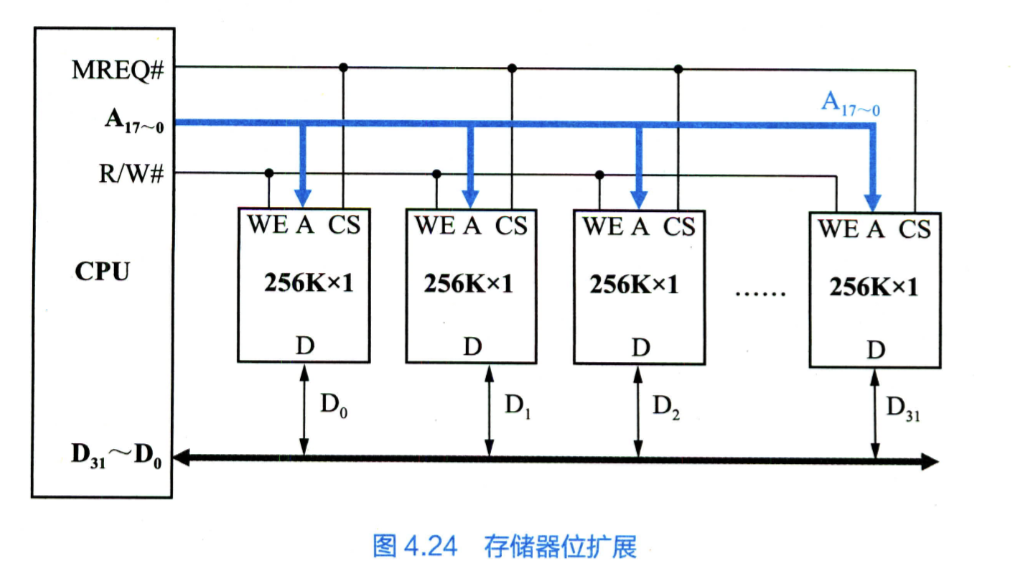
- 位扩展(字长扩展或数据总线扩展)
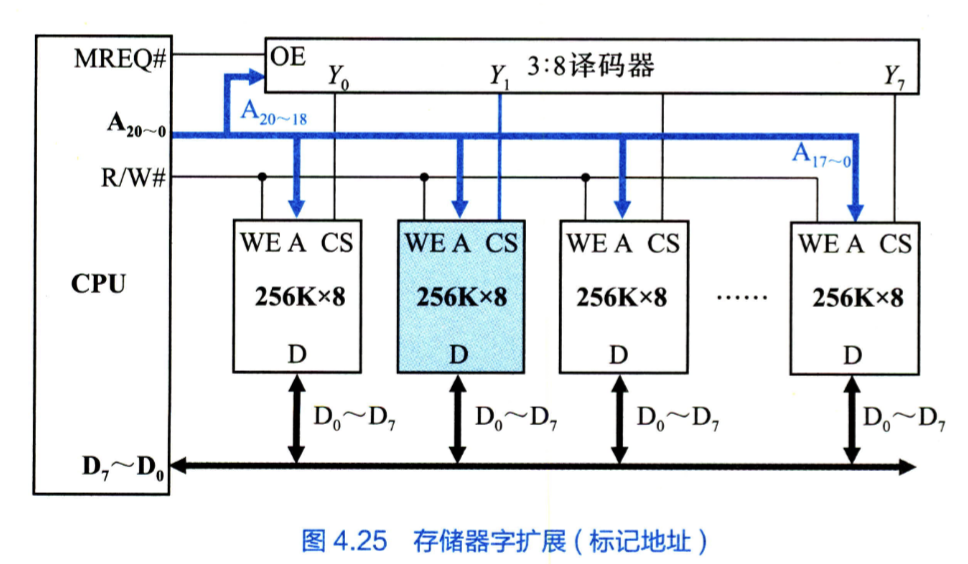
- 字扩展(容量扩展或地址总线扩展)
- 字位同时扩展
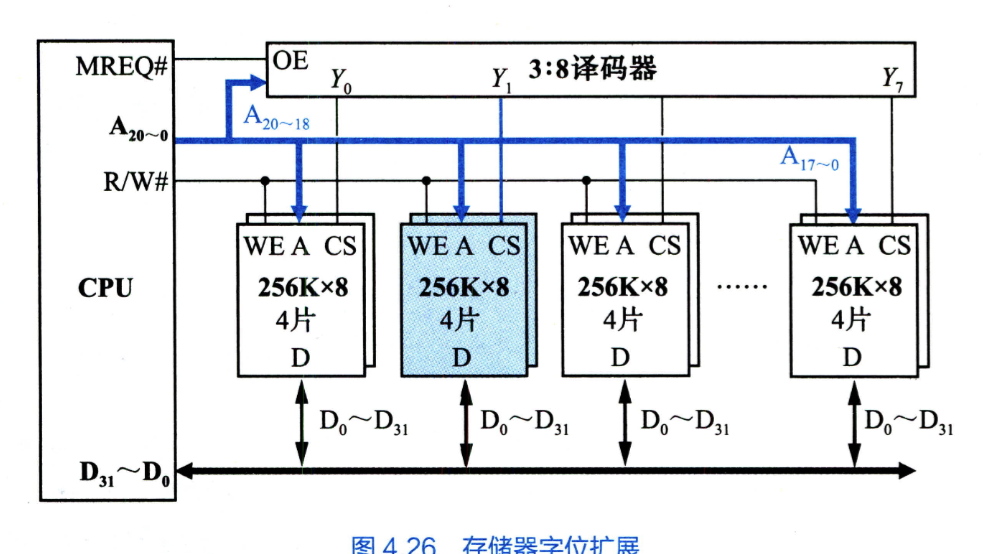
并行主存系统
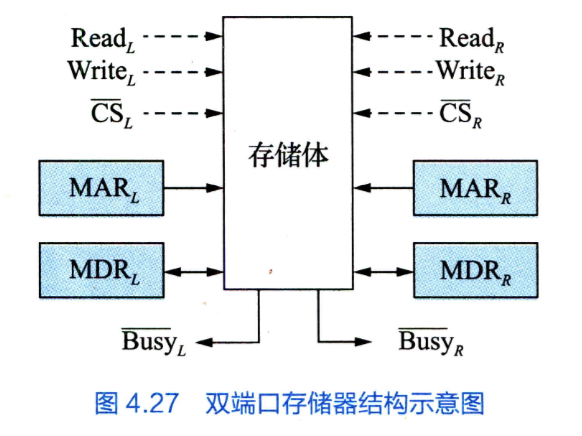
- 双端口存储器
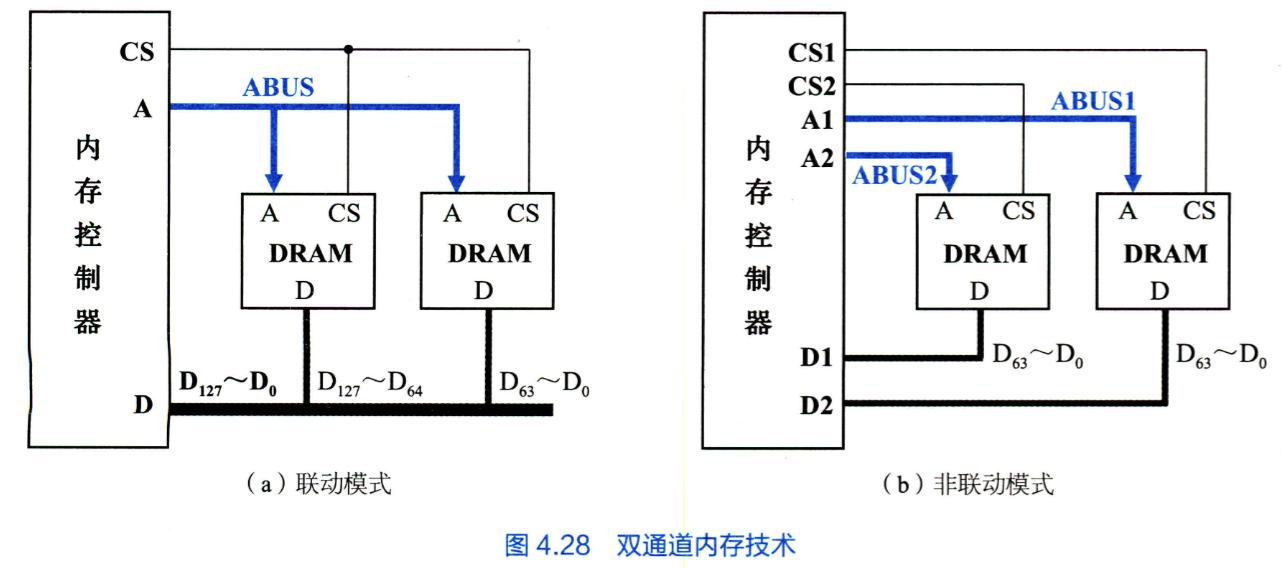
- 单体多字存储器
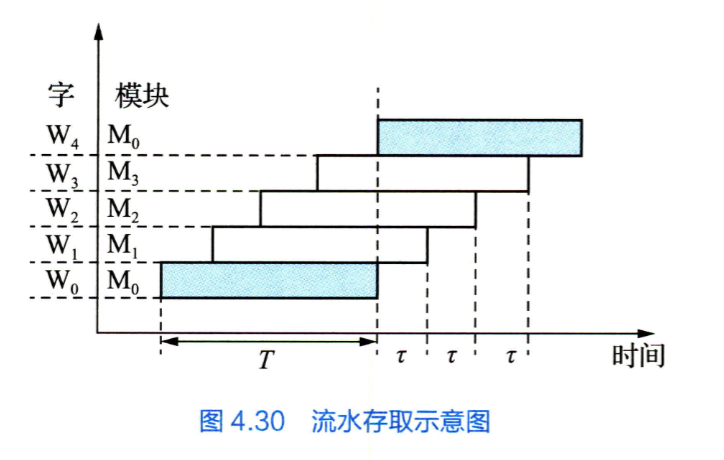
- 多体交叉存储器
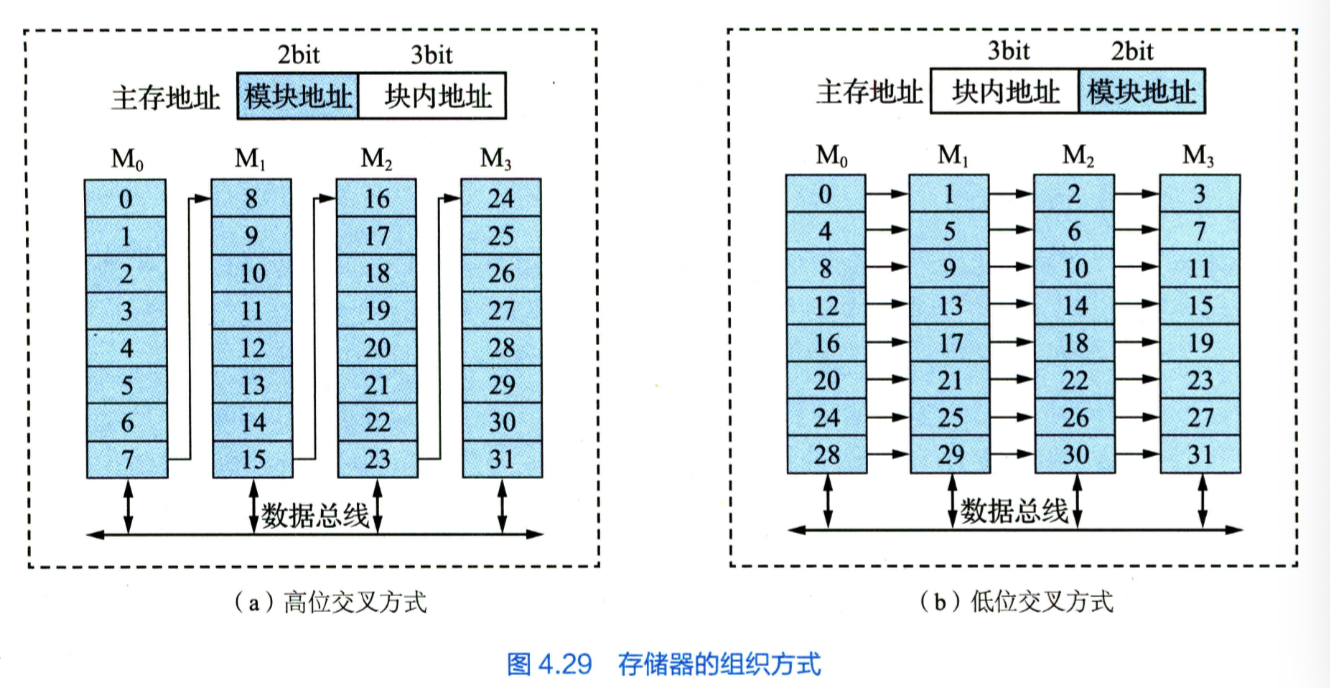
低位交叉流水线存取:
🌟 高速缓冲存储器
cache:CPU 与主存之间的小容量快速 SRAM,利用了 CPU 执行程序的时空局部性。
- 几种映射方式

- 几种淘汰算法
1⃣️ 先进先出算法(First In First Out, FIFO):考虑载入 cache 的时间
2⃣️ 最不经常使用算法(Least Frequently Used, LFU):考虑访问次数最少的行淘汰。缺点:在于某些前期访问多而后期访问少,时间累积对后期
3⃣️ 近期最少使用算法(Least Recently Used, LRU):考虑近期最久未被访问过的行进行淘汰。多行计数,命中则清零。那么这样淘汰最大的就 🌟,采用并行归并比较器比较淘汰。但如果是二路相联则不需要计数器,只要一个最新载入标志位即可。
4⃣️ 随机替换算法
- 写入策略
1⃣️ 写回法
设置一个脏位,修改 cache 不立即修改主存。
2⃣️ 写穿法
cache 写命中时,同时对 cache 和主存中的统一数据块进行修改。
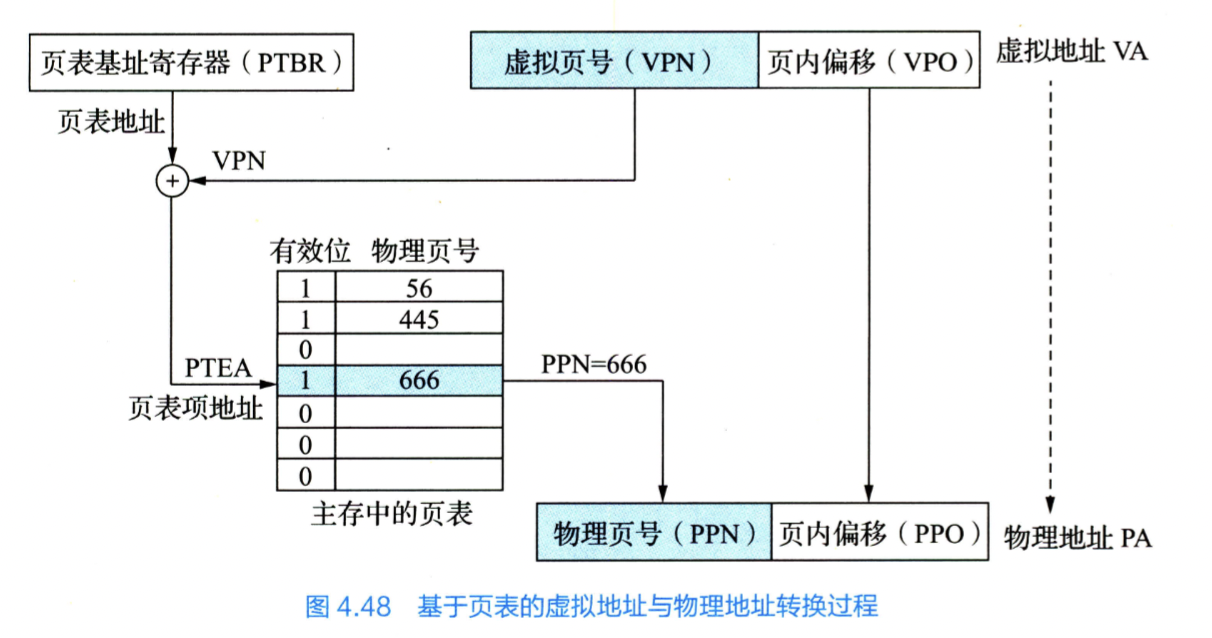
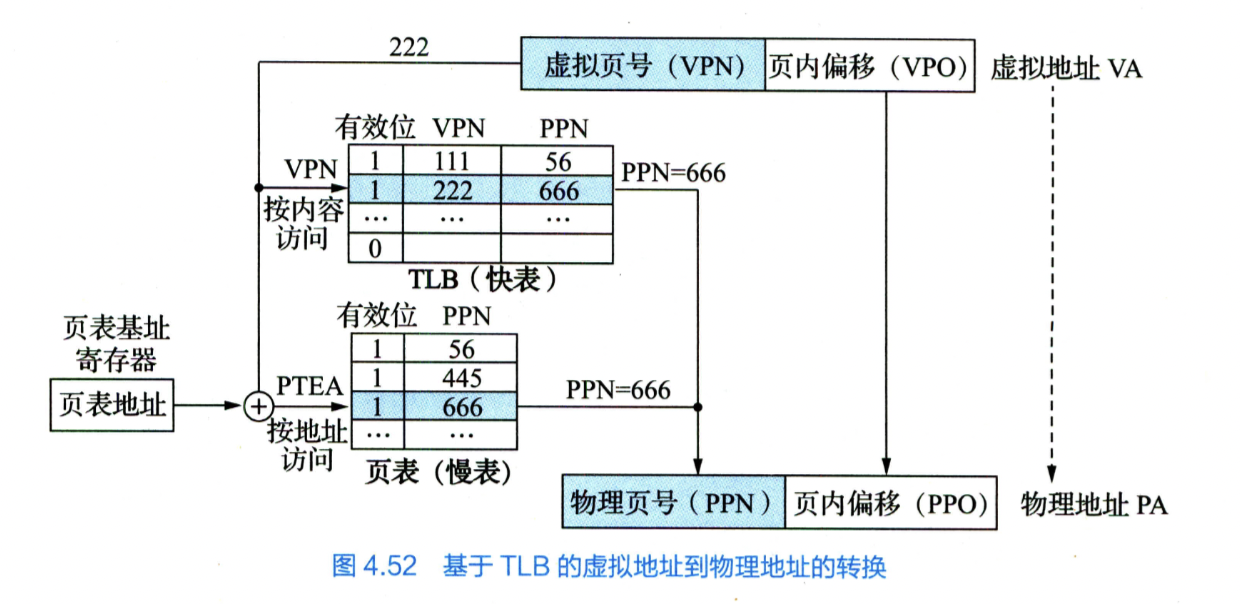
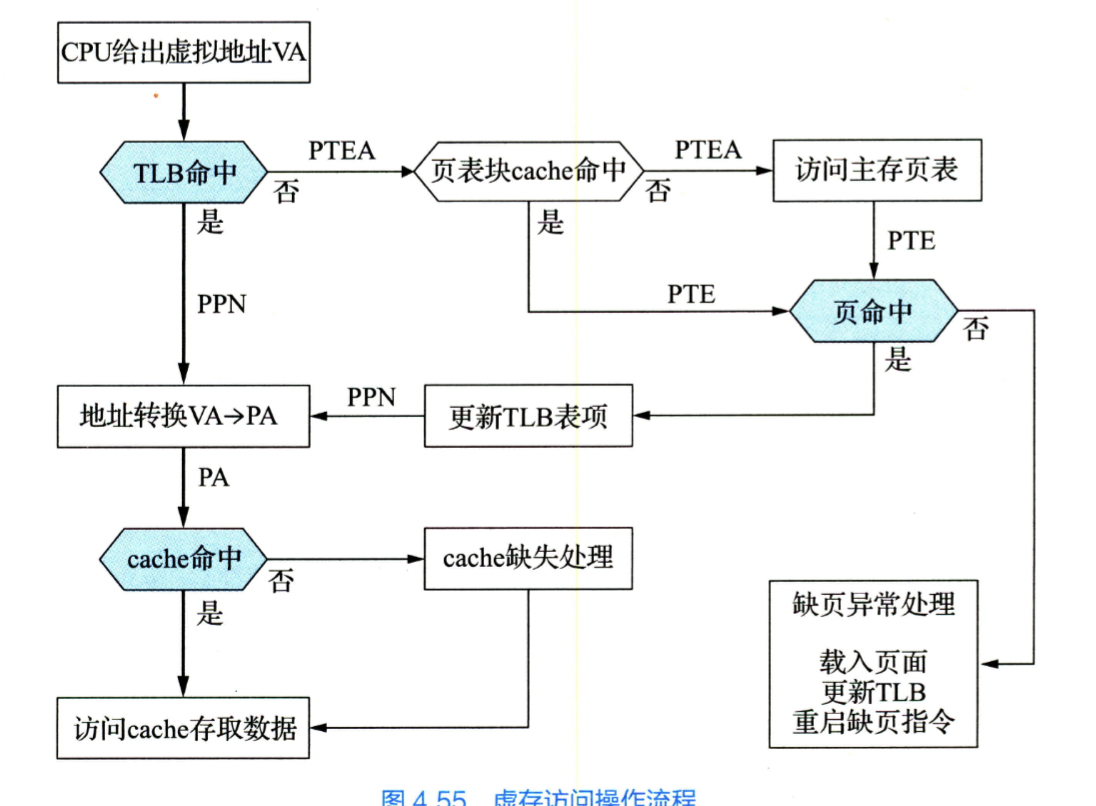
虚拟存储器
指令系统
RISC-V

MIPS

中央处理器 CPU
🐦 🐦 🐦 复习实验去
CPU 延迟
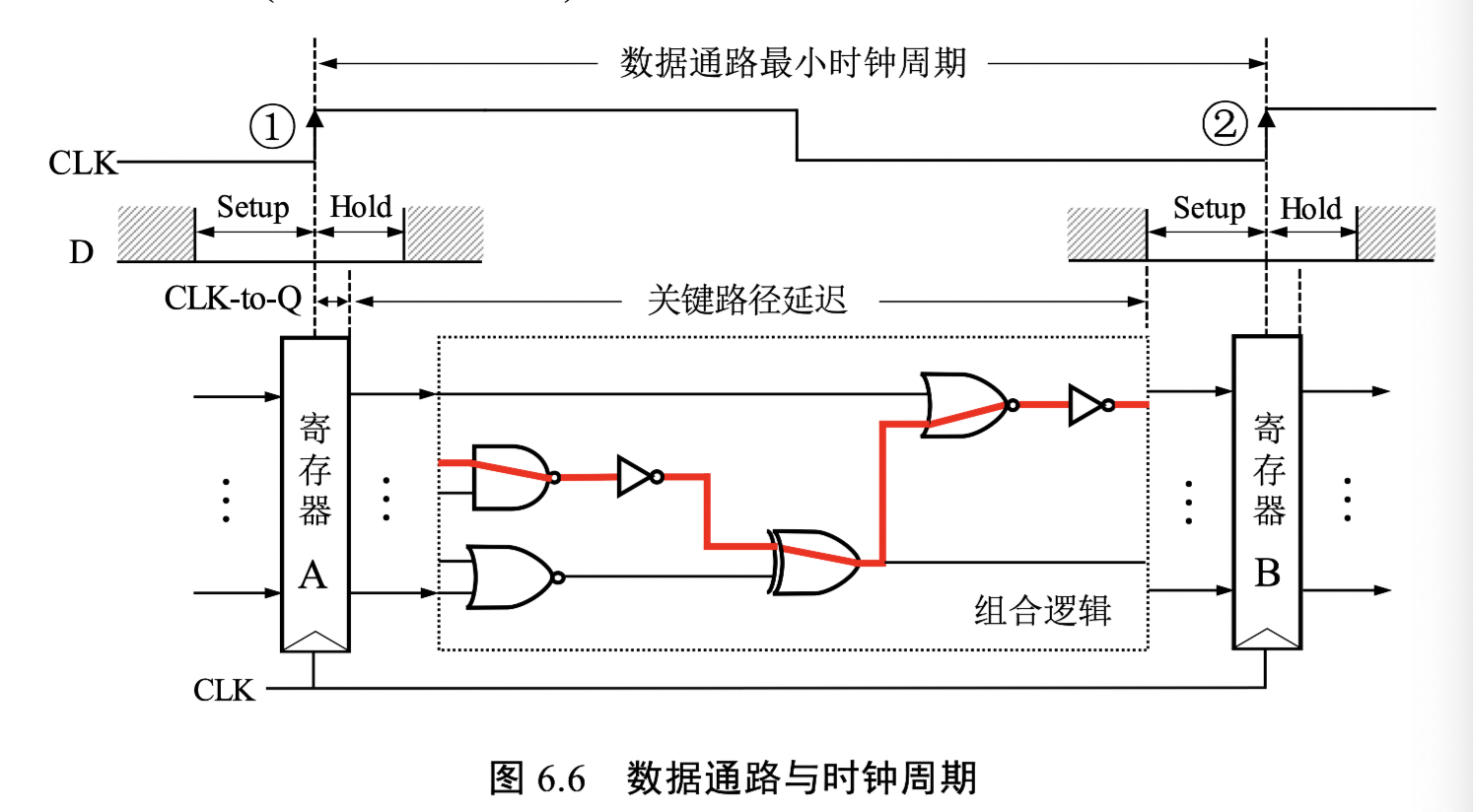
最小时钟周期(需要让组合电路输出稳定)最小时钟周期 > 寄存器延迟 + 组合逻辑关键路径延迟 + 寄存器建立时间
保持时间违例(保持要求不能太高):保持时间 < 寄存器延迟 + 最短路径延迟
单总线 CPU
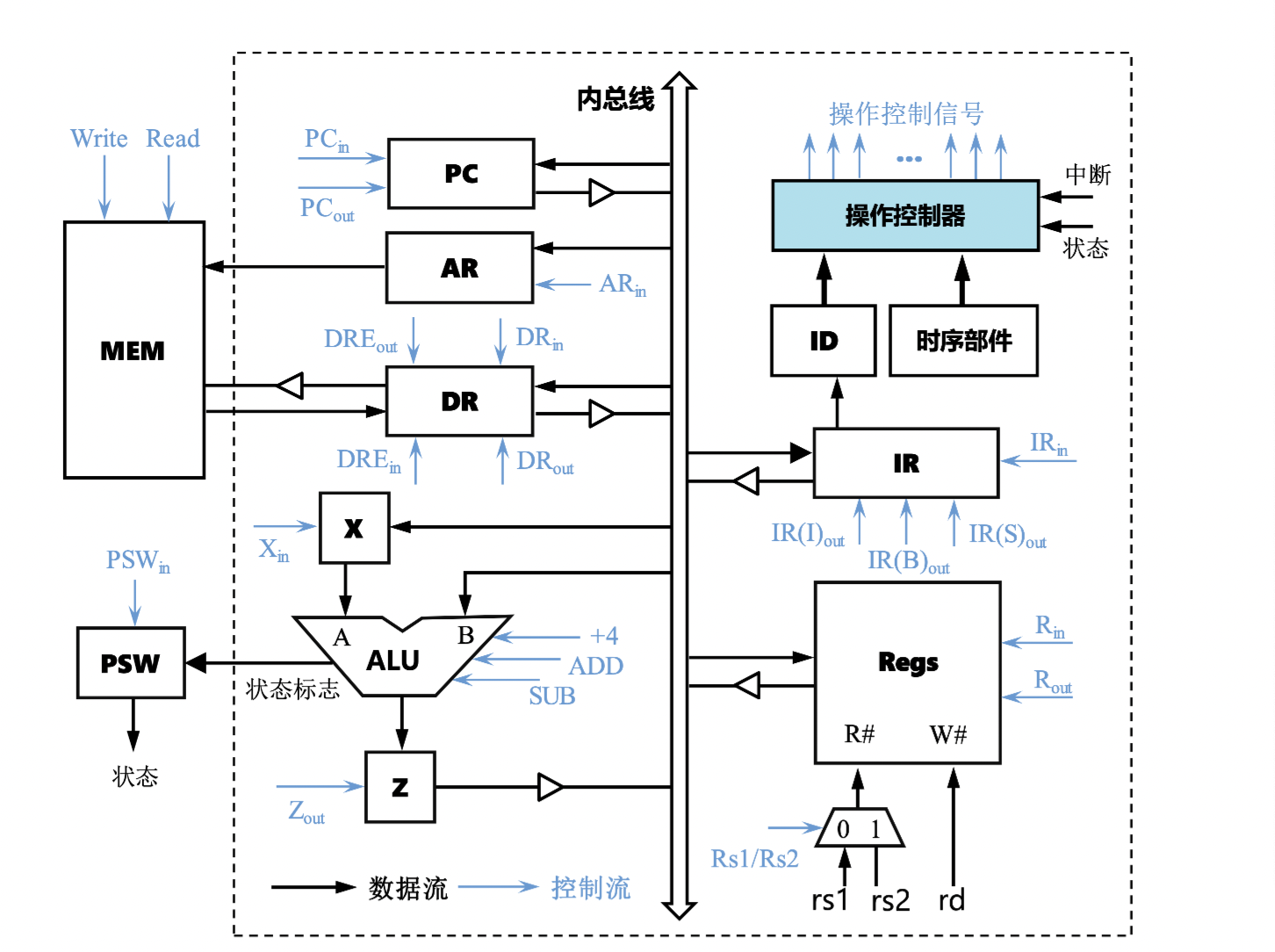
典型 RISV-V 指令

划分数据流与控制流(取指 Mif -> 计算 Mcal -> 执行 Mex)
整体流程:
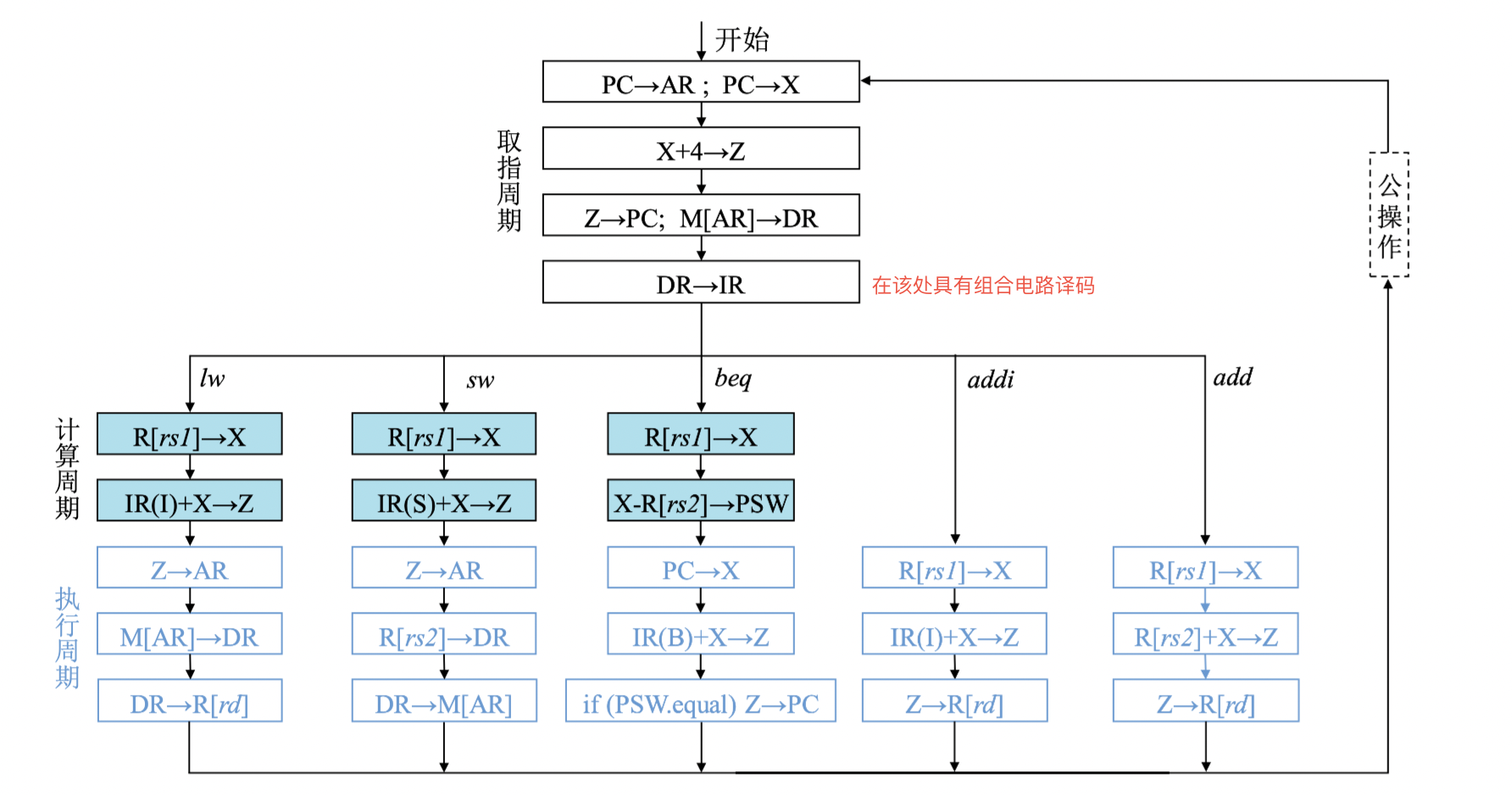
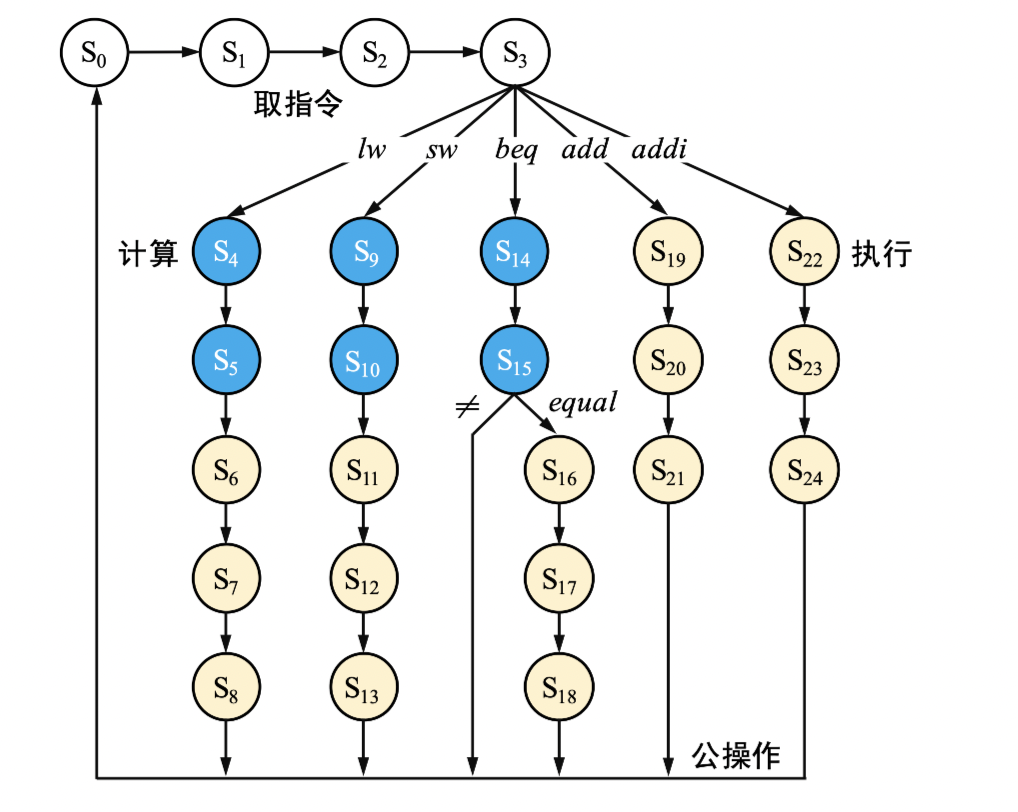
现代时序状态转移:在 equal 处判断是否进入执行周期
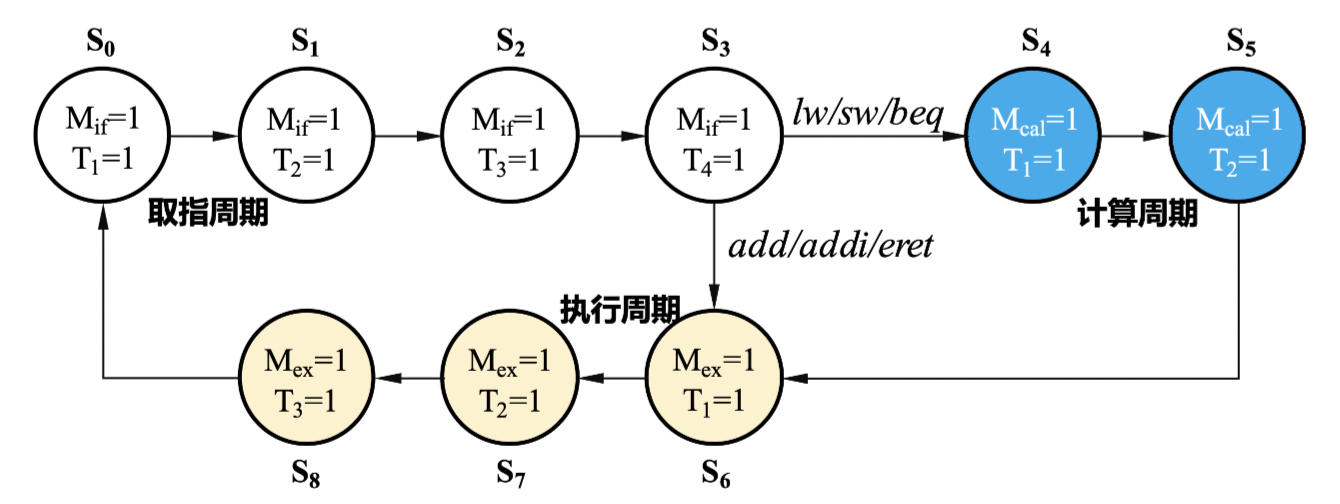
三级时序:在 beq 时先算在判定是否载入 PC
输入输出系统/中断
中断——面向作业学习 🙃
中断屏蔽:不可被中断屏蔽的中断程序打断,可调整优先级
⚠️ 谁被中断是返回谁的,即使只是一点
中断 CPU 占有率计算:基本上是生产者——消费者模型,每次传递是一次中断程序,计算中断程序消耗 CPU 资源以及时间。