

[FAST'24] Combining Buffered I/O and Direct I/O in Distributed File System
Linux 默认 IO 是缓冲 IO,但缓冲 IO 并不是在任何时候都是最优的选择,AutoIO 提供了一个透明的 IO 框架,能够根据 IO 情况适当切换缓冲 IO 与直接 IO,结合了二者的优点。
此外,还有服务端写回、跨文件批处理和延迟内存分配等优化方法。
阅读想法
Abstract
Direct I/O allows I/O requests to bypass the Linux page cache and was introduced over 20 years ago as an alternative to the default buffered I/O mode. However, high-performance computing (HPC) applications still mostly rely on buffered I/O, even if direct I/O could perform better in a given situation. This is because users tend to use the I/O mode they are most familiar with. Moreover, with complex distributed file systems and applications, it is often unclear which I/O mode to use.
In this paper, we show under which conditions both I/O modes are beneficial and present a new transparent approach that dynamically switches to each I/O mode within the file system. Its decision is based not only on the I/O size but also on file lock contention and memory constraints. We exemplary implemented our design into the Lustre client and server and extended it with additional features, e.g., delayed allocation. Under various conditions and real-world workloads, our approach achieved up to 3× higher throughput than the original Lustre and outperformed other distributed file systems that include varying degrees of direct I/O support by up to 13×.
摘要
直接 I/O 允许 I/O 请求绕过 Linux 页面缓存,是20多年前作为默认缓冲 I/O 模式的替代方案引入的。然而,高性能计算(HPC)应用程序仍然主要依赖于缓冲 I/O,即使直接I/O在给定情况下可以表现得更好。这是因为用户倾向于使用他们最熟悉的 I/O 模式。此外,对于复杂的分布式文件系统和应用程序,通常不清楚使用哪种 I/O 模式。
在本文中,我们展示了在哪些条件下两种 I/O 模式都是有益的,并提出了一种新的透明方法,可以动态切换到文件系统中的每种 I/O 模式。它的决定不仅基于 I/O 大小,还基于文件锁争用和内存约束。我们示例性地将我们的设计实现到 Lustre 客户端和服务器中,并用附加功能对其进行了扩展,例如延迟分配。在各种条件和实际工作负载下,我们的方法实现了比原始 Lustre 高 3 倍的吞吐量,并且比其他包括不同程度的直接I/O支持的分布式文件系统高出 13 倍。
介绍
IO 逐渐成为许多科学应用的瓶颈
- IO 量逐渐增加(HPC使用远程的并行文件系统存储数据,随着应用程序核心数量扩展,IO量逐渐发生增加)
- 访问模式发生变化(大量随机访问和元数据访问挑战并行文件系统性能)
缓冲I/O 与直接I/O
- 文件系统利用缓存IO来降低对存储后端进行I/O操作的次数
- 直接IO绕过内核的缓存层直接将IO请求发送到存储系统,当应用程序本身具有缓冲读写时特别有用,避免了”双缓冲区“的情况。然而直接IO约束了对齐标准,该要求严重限制了应用程序对直接IO的使用。
缓冲 IO 一定比直接 IO 性能好吗?难说
注
行文思路:先理论分析,最后实验佐证(实验可列举典型,但一定要广泛测试通用性)。
直观来说,缓冲 IO 的性能应该比直接 IO 性能好,因为缓冲 IO 的预读和回写优化可以使得缓冲 IO 的性能接近内存访问级别。
然而,缓冲 IO 不一定比直接 IO 性能好。原因是内核层面的缓存代价不是免费的,尤其当缓存的数据重用特性很差时。
- 缓冲 IO 会导致额外的复制操作以便在内核缓存和应用程序之间移动数据
- 内核页面缓存和页面管理开销大
- 当内存稀缺时会出发页面回收,由此产生的缓存抖动会显著降低性能
并行文件系统中缓冲I/O还具有额外成本,即为了支持具有强一致性的客户端缓存所需管理复杂的分布式范围锁的成本。
- 如果文件系统仅对并发访问的文件的必要(小)部分加锁,这会要求客户端和锁管理器之间进行多次远程过程调用(RPCs)。
- 而使用较大范围的扩展锁可能会导致客户端之间不必要的锁争用以及大量的锁撤销消息。
两种 IO 模式的优缺点互补。直接 IO 简化了编程,并在许多情况下会产生性能优势。
- 对于大文件的顺序 I/O,顺序 IO 可以提供相同甚至更好的性能,并且 CPU 和内存开销小很多
- 当许多具有交错的文件偏移量的节点同时修改一个文件时,还可以提高小写的性能
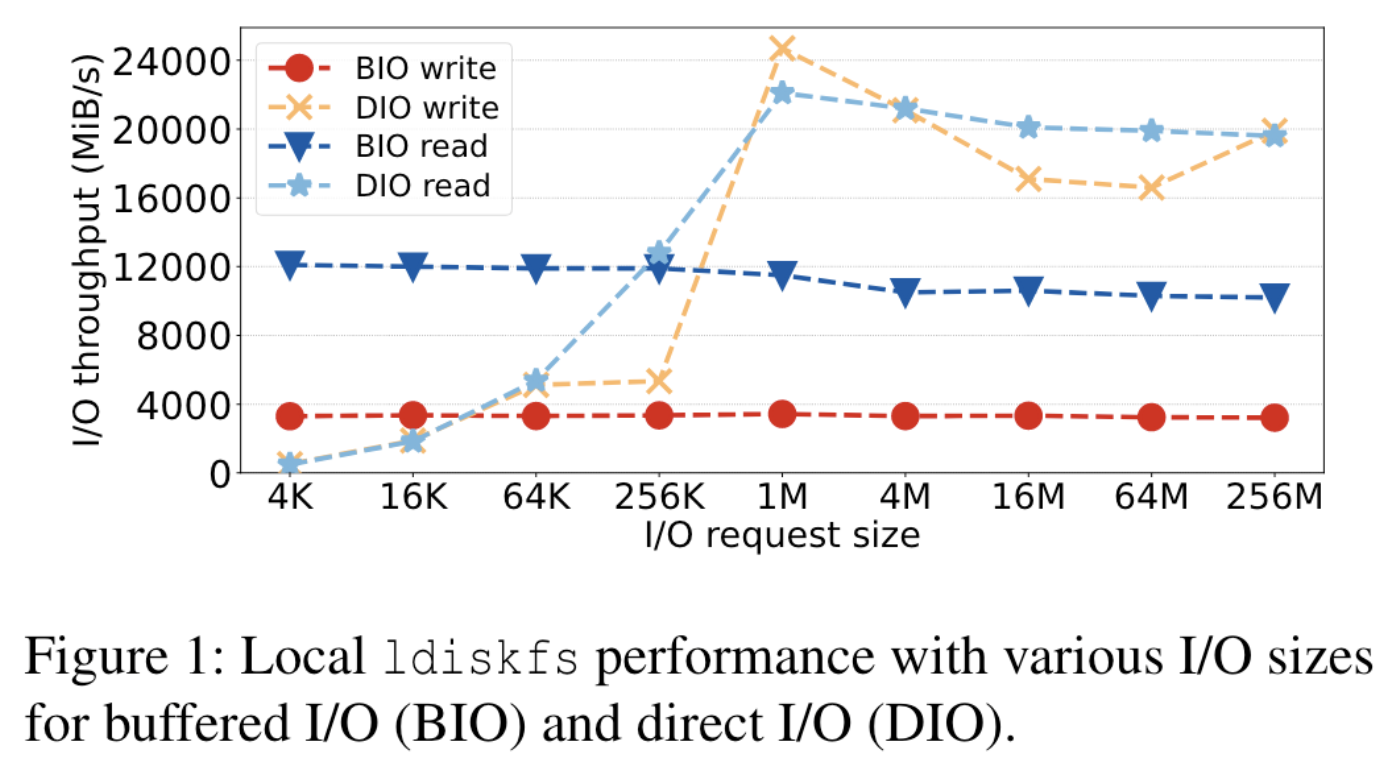 图一描述了两种I/O模式实验对比的情况。 实验方案:16个线程在本地Lustre ldiskfs设备上运行fio基准测试,每个线程使用单独的文件,在I/O大小介于4 KiB到256 MiB之间时,读写了20 GiB的数据。测试了直接IO和缓冲IO的性能。 实验结果:缓冲I/O的写入聚合和预读优化导致写入性能稳定在3 GiB/s,读取性能为11 GiB/s,几乎独立于访问大小。直接I/O在小IO大小性能明显低于缓冲IO,但在更大的IO大小性能比缓冲IO好。 实验结论:缓冲I/O的性能瓶颈取决于可用于缓存的内存量和页缓存开销,并且与可用的存储带宽或连接存储系统的数量无关。直接I/O在小IO情况下受到同步写入存储后端延迟影响,在大IO情况下受益于不执行不必要的复制操作和页面缓存管理,从而更充分利用后端SSD性能。
图一描述了两种I/O模式实验对比的情况。 实验方案:16个线程在本地Lustre ldiskfs设备上运行fio基准测试,每个线程使用单独的文件,在I/O大小介于4 KiB到256 MiB之间时,读写了20 GiB的数据。测试了直接IO和缓冲IO的性能。 实验结果:缓冲I/O的写入聚合和预读优化导致写入性能稳定在3 GiB/s,读取性能为11 GiB/s,几乎独立于访问大小。直接I/O在小IO大小性能明显低于缓冲IO,但在更大的IO大小性能比缓冲IO好。 实验结论:缓冲I/O的性能瓶颈取决于可用于缓存的内存量和页缓存开销,并且与可用的存储带宽或连接存储系统的数量无关。直接I/O在小IO情况下受到同步写入存储后端延迟影响,在大IO情况下受益于不执行不必要的复制操作和页面缓存管理,从而更充分利用后端SSD性能。
背景和动机
本节对缓冲IO和直接IO进行详细的对比分析,然后介绍了页面缓存和IO锁争用对缓冲IO的性能影响以激发在HPC系统中实现更高的IO性能的设计。
直接IO vs. 缓冲IO

缓冲IO的特点:默认的文件访问模式,易于集成。优点是在数据多次访问隐藏慢速存储访问的延迟。 直接IO的特点:不需要进行数据复制,但需要满足特定的大小和对齐约束。 缓冲IO的缺点:1. 数据不能多次重用时,单流性能较差;2. 多个节点的多个进程写入共享文件时会产生许多锁冲突;3. 在单个节点内,多个核对单个文件进行写操作时,页面缓存内部也会发生争用。 直接IO的缺点:1. 不能隐藏慢速设备或小 IO 延迟;2. 直接IO要求IO大小和内存中的偏移量与页面大小对齐,因此大多数应用程序需要作出显著修改才能使用。
页面缓存和数据拷贝对缓冲IO的影响
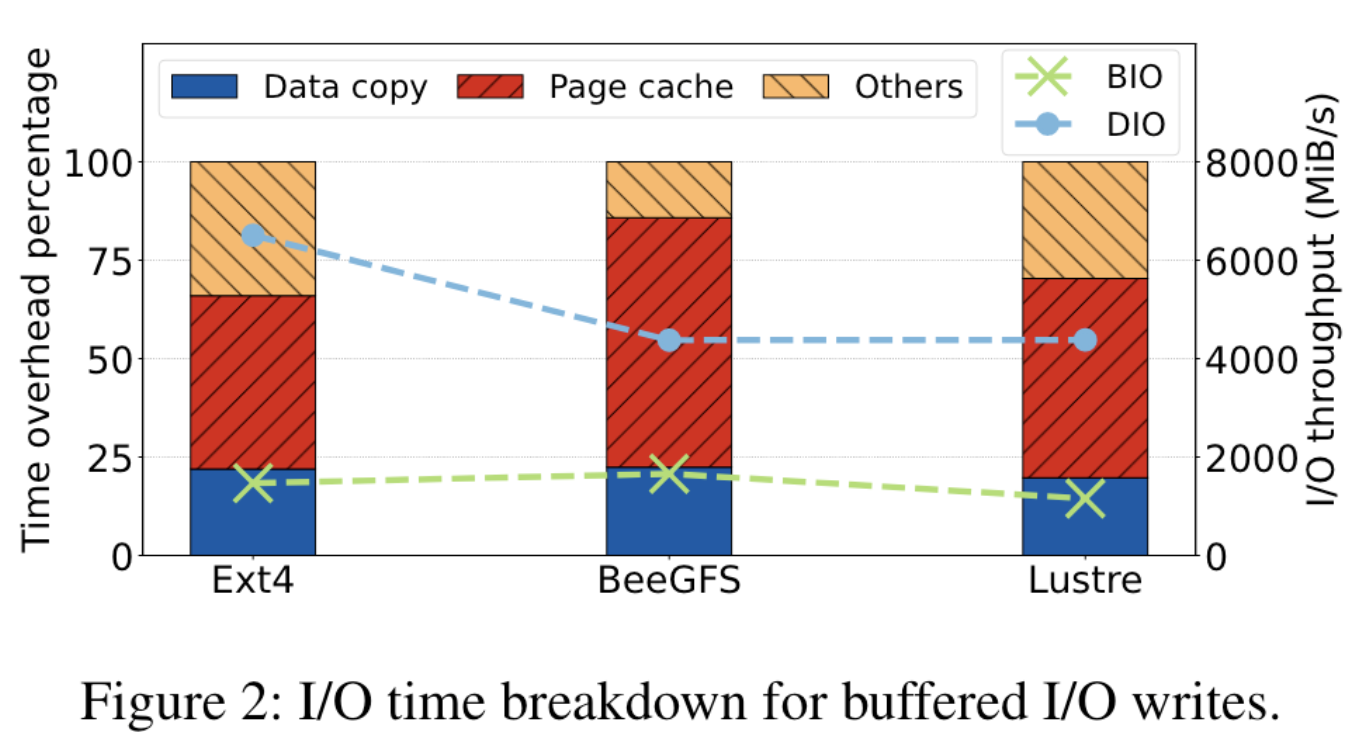
实验单线程顺序写入总共2,560 GiB大小的数据,使用了IOR基准测试工具和perf性能分析程序来收集和分析对应的性能和追踪数据。
实验结果(显示在图2中)表明,对于本地文件系统Ext4和网络文件系统Lustre与BeeGFS,这些系统在复制数据到页面缓存和页面缓存管理上花费了约20%的时间和超过40%的时间。
图表还展示了缓冲I/O的性能结果以及在相同设置中直接I/O的性能。本地文件系统Ext4上的直接I/O可以将性能提高近五倍,而Lustre和BeeGFS的增益较小,因为它们需要通过网络进行额外的批量数据传输。
Lustre 中的 IO 锁定和争用
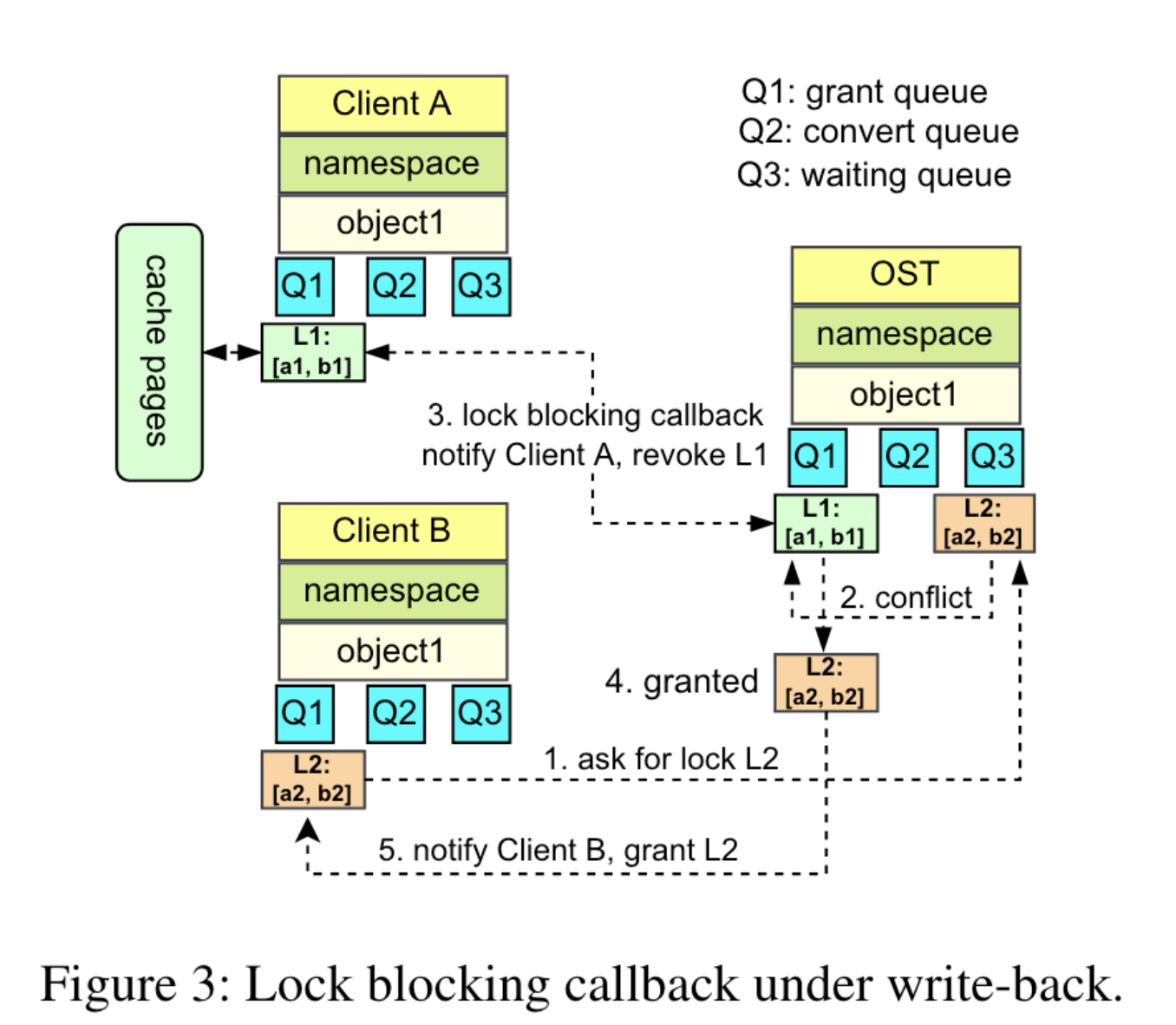
缓冲区锁机制是检测冲突-回调撤销-授权通知的方式。在这种情况下,多进程的锁冲突解决和锁的乒乓效应代价昂贵,因此提出了一种使用直接 IO 和服务器端锁定的机制消除 IO 的锁回调。
设计和实现
设计分为四个部分:自适应IO模式选择算法、服务器端自适应锁定、服务端延迟分配、未对齐直接IO支持。
AutoIO: 结合缓冲 IO 和直接 IO
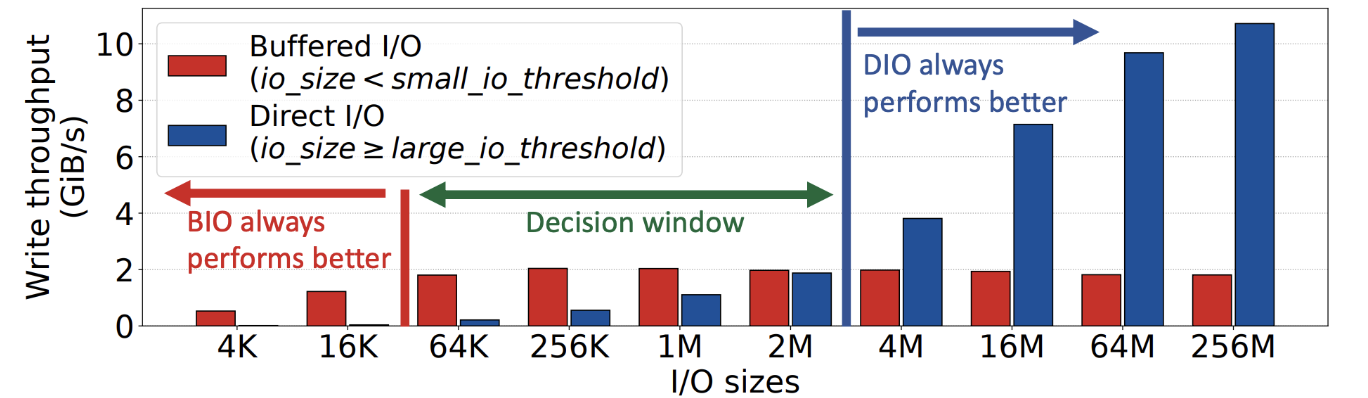
初步实验得到如图结果,确定缓存 IO 和直接 IO 对 IO 大小偏好的阈值。
- 在小 IO 范围内,始终采用缓冲 IO
- 在大 IO 范围内,始终采用直接 IO
- 在决定窗口内,优先使用缓冲 IO,当检测到锁争用状态(Lustre已存在的机制)、内存压力(缓存页使用>95%)、缓存重用不明显时切换到直接 IO
对于直接IO,不采用客户端副本锁机制,而是直接将直接IO请求发送至服务器端,由服务器侧锁保证IO完成并且立即释放。
为了确定锁的争用程度,服务器通过滑动窗口计数器对客户端进行回复。即服务器在 4s 内观察到了 16 个以上的冲突锁请求,则认为文件对象处于争用状态,向客户端报告。
Server-side write-back
Lustre 文件系统在服务器端的所有I/O请求都会被I/O服务线程立即提交给存储,以避免内存争用(写穿模式)。尽管对于处理大型I/O请求非常有效,但写穿(Write-through)模式并未充分利用可用的磁盘带宽来处理小型I/O请求。为了改善服务器对于延迟敏感型使用案例的I/O性能,增加了自适应写回(Write-back)缓存模式,即所有小于64 KiB的I/O请求都使用页面缓存在写回模式下处理,其余写穿。
Cross-file batching
Lustre客户端会积累应用程序的脏页,并将它们作为大容量RPC(1 MiB)异步发送到存储服务端。这种方法避免了许多小型RPC的产生,因此在网络和磁盘效率方面更加高效。
然而,对于许多小文件而言,可能没有足够的脏页来填满一个完整的批量RPC,这会延迟写回操作并导致很多小RPC被发送,因为I/O RPC发送脏页到存储服务器是限制在单个文件上的。
跨文件批处理是一个针对涉及许多小文件多次小写操作的场景的优化策略。它可以批量将多个文件的脏页整合进一个大的批量RPC,提高网络效率。
Delayed allocation
为了解决在多客户端并行写入单个文件时产生的严重文件碎片化问题,在服务器端的写回模式下在不立即在磁盘上分配数据块,而是在内存中为这些写请求预留空间,并在状态树中维护这些数据块的状态,最后一次性在磁盘上分配数据块。