[SOSP'23] Ditto: An Elastic and Adaptive Memory-Disaggregated Caching System
Ditto 是一个部署在分离内存架构上的弹性自适应的缓存系统。
分离内存架构很好地池化了计算资源和内存资源,但缓存系统在该架构下面临着执行缓存算法和动态资源变化的两大挑战。Ditto 提出了以客户端为中心的缓存框架和分布式缓存自适应方案来解决这两大挑战。
启发:
- 利用哈希槽可以快速访问热点数据;
- FIFO队列不一定需要显式的,使用顺序id +全局计数器也能实现;
- 可以通过机器学习算法简单适应动态资源的变化。
背景
部署在传统 CPU 与内存耦合在一起的整体式服务器集群的缓存系统具有两大问题。
首先是资源利用效率低下。分配给应用程序的虚拟机一般是有一定比率的CPU内核和内存。应用程序无论是需要CPU资源还是内存资源,都需要增加虚拟机的数量。这时候未被使用的CPU资源或者内存资源就会被浪费掉,具有资源利用效率低下的问题。
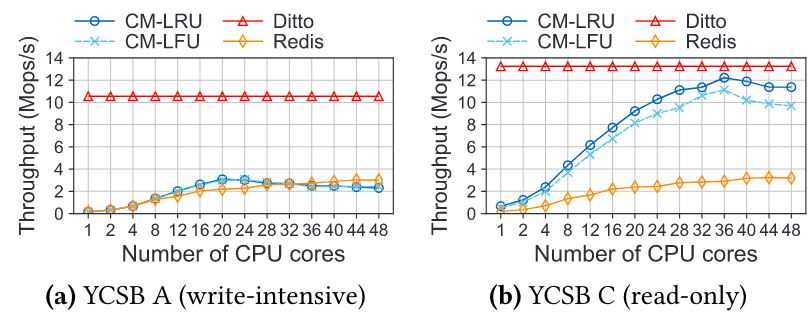
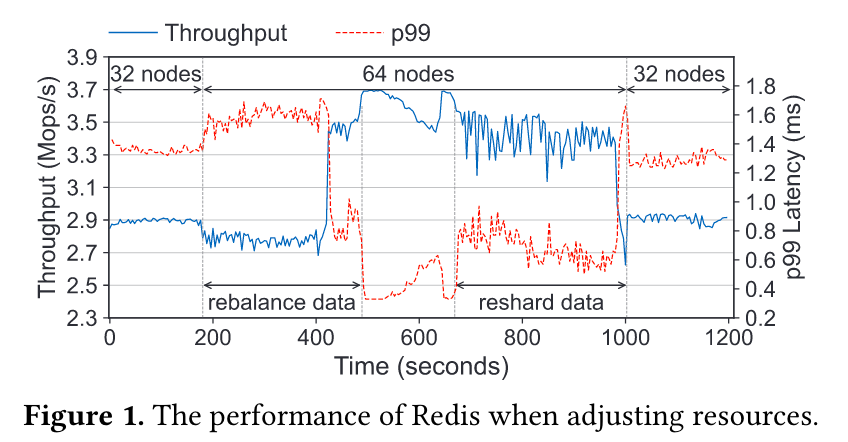
第二个问题是资源调整速度较慢,刚刚提到,资源调整是虚拟机的增减,那么当缓存系统调整资源时,需要将数据重新分片并进行相应的迁移,这使得资源调整的速度较慢。并且,迁移数据占用了数据带宽,使得这段时间的性能有所损失。如图所示表示了 redis 在资源调整时的性能表现。
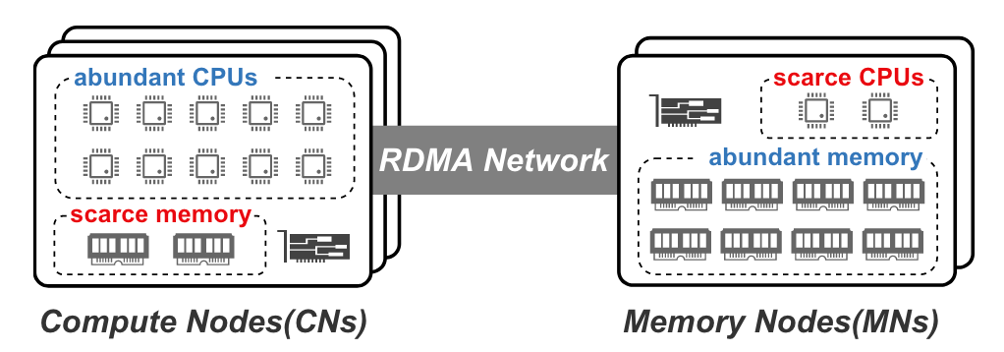
分离内存架构可以缓解以上问题。分离内存由计算池和内存池构成。计算池由大量CPU核和小DRAM缓存组成,内存池则由大量DRAM和少量核组成,计算池通过高速网络(如RDMA,CXL)绕过CPU直接访问内存池中的内容。分离内存架构一方面可以单独调整CPU/内存资源,避免资源浪费;另一方面避免了资源调整时的数据迁移。
挑战
挑战 1: 在分离内存架构下执行缓存算法存在挑战
数据访问热度统计困难
然而,在分离内存架构下执行缓存算法存在挑战。
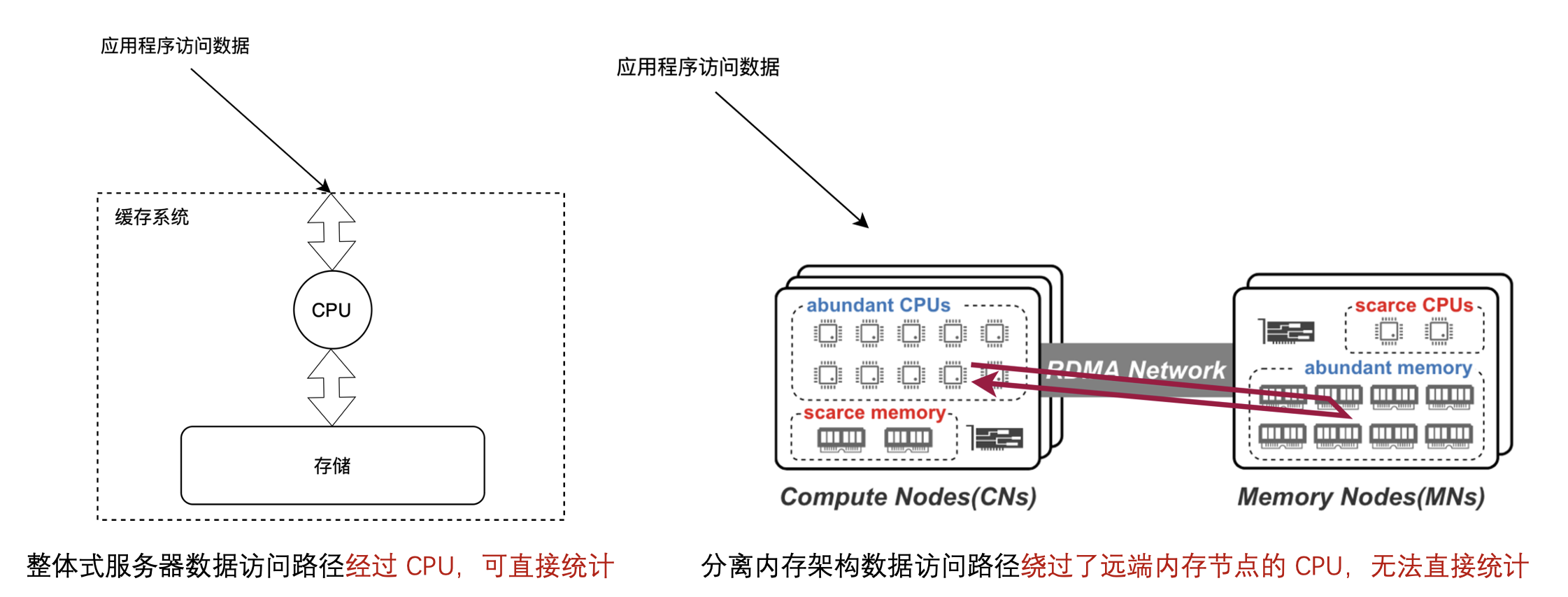
首先是在数据的热度统计上有困难,传统的整体式服务器的数据访问路径是经过CPU的,所以可以直接统计;
但在分离内存架构数据访问路径中的RDMA是绕过了远端内存节点的CPU,所以不能够直接统计。
高效淘汰缓存项困难
其次是如何高效地淘汰缓存项。缓存的淘汰算法需要相应的数据结构支撑,例如 LRU 需要双向链表和哈希表、LFU 需要哈希表和最小堆、FIFO 需要队列结构等等。分离内存需要在计算节点的客户端维护相应的数据结构和锁结构,相应的维护过程需要多个 RTT 导致网络争用。
挑战 2:动态资源的变化影响缓存命中率
计算资源的调整、内存资源的调整让缓存算法有不同程度的命中率变化。所以说,缓存系统需要根据不断变化的资源设置而动态选择最佳的缓存算法进行淘汰缓存项。然而,分离内存去中心化和分布式的性质,在这里实现着用适应性是困难的。

方案
总览
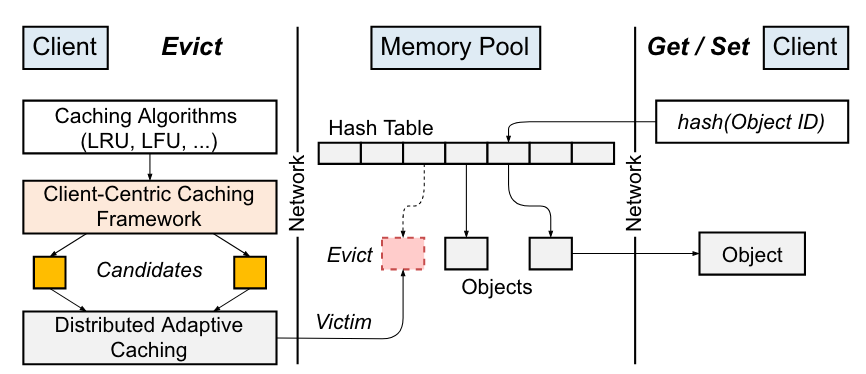
Ditto 缓存系统设计大致分为两个模块。一方面是 Get/Set 缓存项的存储模块,实质上是分离内存上的哈希表,类似 RACE HASHING。另一方面是缓存项的淘汰模块,这个是 Ditto 的设计点所在,即以客户端为中心的缓存框架和分布式自适应方案。
以客户端为中心的缓存框架
以客户端为中心的缓存框架解决了在分离内存上执行缓存算法时评估对象热度和选择淘汰候选对象的挑战。
在介绍以客户端为中心的缓存框架前,先介绍一下缓存替换算法常见的访问信息,例如 size,插入、访问时间戳,访问频次等等。
Ditto 将这些访问信息存储在内存节点中,采用两个 RDMA 操作对元数据进行更新,对于无状态元数据直接采取 RDMA_WRITE 覆盖写入,对于有状态元数据例如频次则采取 RDMA_FAA 原子增加。

框架首先提出了样本友好型哈希表,样本友好型哈希表的目的是方便客户端采样各缓存项的访问信息。它将最广泛应用的元数据存储在哈希槽中,其余的元数据则与对象一起存储。这样一来仅通过一次RDMA_READ 便可以采样许多缓存项对应的元数据内容。
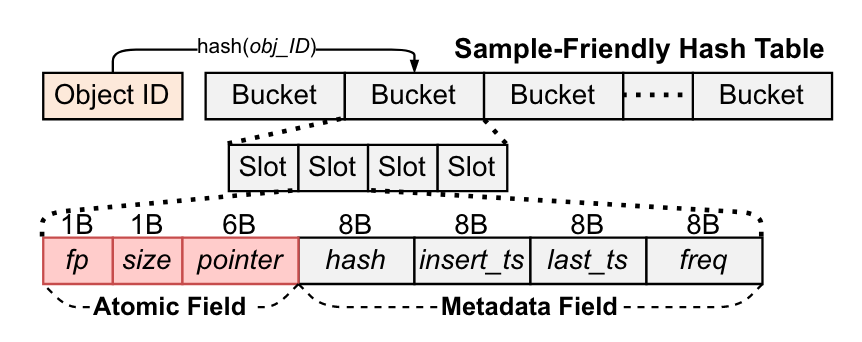
虽然样本友好型哈希表方便了客户端对访问信息进行采样,但它更新元数据仍然需要两个RDMA操作,尤其是对访问频次的更新使用了开销较大的 RDMA_FAA 操作。
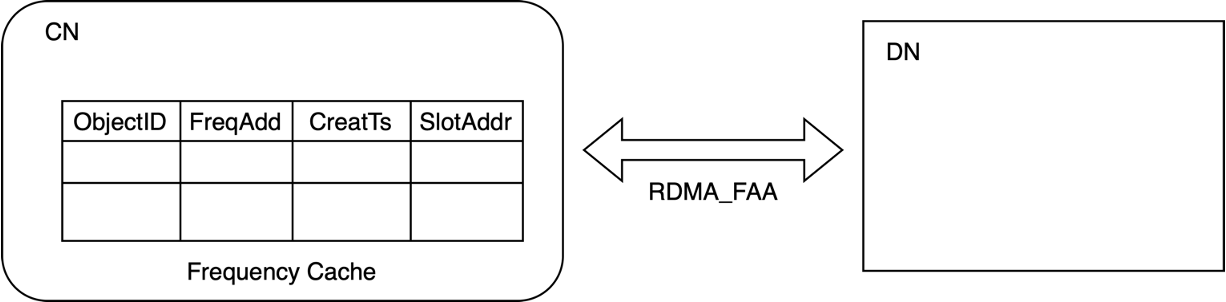
频率计数器缓存就是用来见效开销较大的 RDMA_FAA 操作。
它在计算节点处设立频率计数器缓存,当数据访问时仅在本地对缓存计数加一,在两种情况时才会使用 RDMA_FAA 远程对内存节点的频率计数进行更新。
一是频率计数缓存满时,二是频率计数超过了预设的阈值时。
分布式自适应方案
分布式缓存自适应方案解决了如何在分离内存上以分布式和以客户端为中心的方式实现自适应缓存方案选择。
多臂老虎机问题(multi-armed bandit problem, MAB)
多臂老虎机是一个有多个拉杆的老虎机,每一个拉杆的中奖几率是不一样的,问题是:如何在有限次数内,选择拉不同的拉杆,获得最多的收益。
缓存自适应方案就是多臂老虎机问题,每种缓存淘汰策略为老虎机的拉杆,选择拉拉杆为选择使用何种淘汰策略。使用遗憾最小化算法来解决该类问题,即当缓存项被淘汰算法淘汰后仍然被访问,则降低相对应淘汰策略的权重,按照权重随机选择淘汰策略。
调整专家(淘汰策略)权重的方法:
维护一个名为驱逐历史的固定大小的 FIFO 队列,如果该队列的缓存项被访问到,则降低相应淘汰项对应的专家的权重。
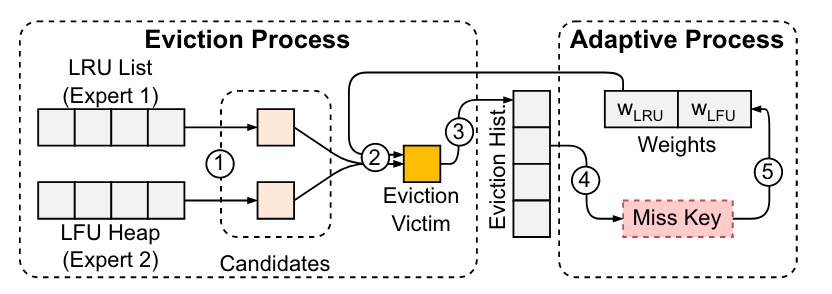
问题:
- 全局 FIFO 队列代价昂贵
- CN 间专家权重同步开销大
轻量级淘汰历史表(内嵌淘汰历史条目+逻辑 FIFO 队列)
内嵌历史条目:淘汰历史条目不额外存储,而是复用了哈希表中的条目空间。历史条目重点记录了该缓存项被淘汰时的专家位图。
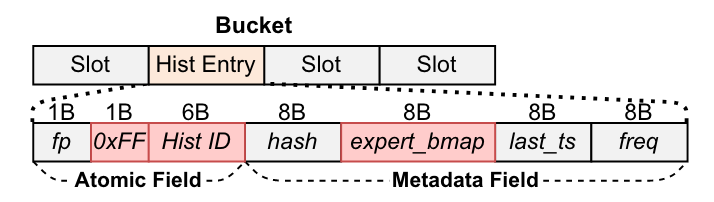
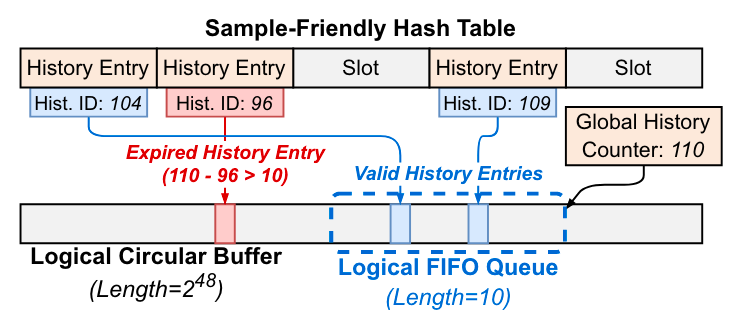
逻辑 FIFO 队列:FIFO 队列为隐式的,其维护了一个全局历史计数器标志了 FIFO 队列的末尾,缓存项被淘汰时历史 ID 记录为最新的历史计数器并加一。通过历史 ID 与当前全局计数器比较可以了解被淘汰的缓存项是否处于 FIFO 队列中。
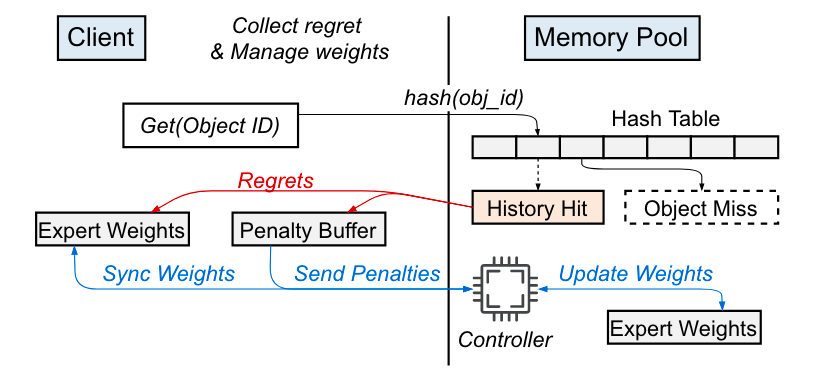
惰性专家权重更新
核心思想为尽可能本地批量处理遗憾:
- 每个 CN 客户端维护一个本地专家权重,客户端淘汰时权重以本地专家权重为准。
- 当 CN 客户端访问到缓存项的“遗憾”时,对本地的专家权重进行调整并将其存储在本地缓冲区中。
- 当本地缓冲区超过阈值时,CN 发起 RPC 将遗憾惩罚应用在全局专家权重中,并将新权重同步至本地专家权重。
权重调整公式为 发,其中 λ 为学习比率,d 为给定的惩罚因子,t 为其在淘汰历史队列的位置
测试
在 Redis 中应用的表现
- Ditto 实现了动态调节 CPU 和内存资源,更具灵活
- 调整资源时无需做数据迁移,调整资源更加敏捷
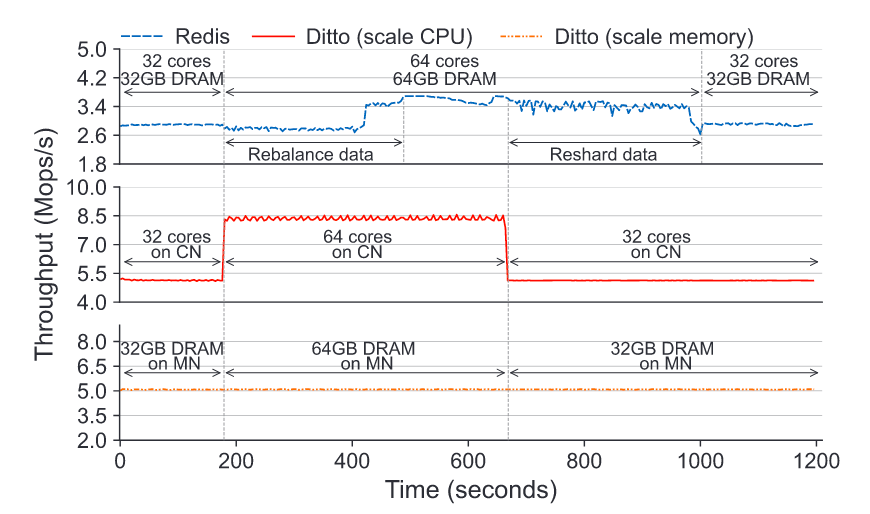
3.6× 吞吐量(真实负载) 9× 吞吐量(YCSB)
- Ditto 仅用 RDMA 单边原语记录访问信息
- Ditto 以无锁的方式淘汰缓存项