

[FAST'23] More Than Capacity: Performance-oriented Evolution of Pangu in Alibaba
本文介绍了阿里的盘古存储系统如何随着硬件技术和业务模式不断发展,以提供高性能、可靠、低延迟的存储服务。第一阶段,创新文件系统和用户空间存储操作系统充分利用 SSD 和 RDMA 技术,第二阶段,充分利用升级的硬件的系统设计。
Abstract
This paper presents how the Pangu storage system continuously evolves with hardware technologies and the business model to provide high-performance, reliable storage services with a 100-μs level of I/O latency. Pangu’s evolution includes two phases. In the first phase, Pangu embraced the emergence of solid-state drive (SSD) storage and remote direct memory access (RDMA) network technologies by innovating its file system and designing a user-space storage operating system. As a result, Pangu substantially reduced its I/O latency while providing high throughput and IOPS. In the second phase, Pangu evolved from a volume-oriented storage provider to a performance-oriented one. To adapt to this business model change, Pangu upgraded its infrastructure with storage servers of much higher SSD volume and RDMA bandwidth from 25 Gbps to 100 Gbps. It introduced a series of key designs, including traffic amplification reduction, remote direct cache access, and CPU computation offloading, to ensure Pangu fully harvests the performance improvement brought by hardware upgrades. Other than technology innovations, we also shared our operating experiences during Pangu’s evolution, and discussed important lessons learned from them.
摘要
本文介绍了盘古存储系统如何随着硬件技术和业务模式不断发展,以提供高性能、可靠、I/O延迟为100 μ s的存储服务。盘古的演变包括两个阶段。在第一阶段,盘古通过创新其文件系统和设计用户空间存储操作系统,拥抱固态硬盘(SSD)存储和远程直接内存访问(RDMA)网络技术的出现。因此,盘古大幅降低了I/O延迟,同时提供了高吞吐量和IOPS。
在第二阶段,盘古从面向卷的存储提供商发展成为面向性能的存储提供商。为了适应这种商业模式的变化,盘古将其基础设施升级为存储服务器,其SSD容量和RDMA带宽从25 Gbps升级到100 Gbps。它引入了一系列关键设计,包括流量放大减少、远程直接缓存访问和CPU计算卸载,以确保盘古充分收获硬件升级带来的性能提升。除了技术创新,我们还分享了盘古发展过程中的运营经验,并讨论了从中吸取的重要教训。
Intro
Pangu 是阿里的统一存储平台,例如 EBS(Elastic Block Storage,弹性块存储),OSS(Object Storage Service,对象存储)等云服务都是建立在 Pangu 之上的。
Pangu1.0
Pangu1.0 容量为导向的存储服务。由商用 CPU、 HDD 和 Gbps 级数据中心网络组成,ms 级 I/O 延迟。 盘古1.0基于 Linux Ext4 文件系统和内核级 TCP进行分布式内核空间文件系统的设计,并随着不同存储服务的需要逐渐增加对多种文件类型的支持,例如临时文件、日志文件和随机访问文件。
Pangu2.0
Pangu2.0 设计并开发 2.0 版本使用 SSD 和 RDMA 技术,目标是提供百微秒级延迟的高性能存储服务。虽然 SSD 和 RDMA 能够在网络中实现高性能操作,但在生产过程中观察到以下问题:
- 在 SSD 性能不佳的文件类型:盘古1.0使用的多种文件类型,尤其是允许随机访问的文件类型,在SSD上性能表现较差。这是因为SSD在连续操作上能够实现高吞吐量和高输入输出操作每秒(IOPS),但随机访问性能却较差。
- 内核空间软件栈跟不上 SSD 和 RDMA 的高性能:内核空间数据复制和频繁中断
- 数据中心架构的范式转变:从以服务器为中心到资源分离的数据中心架构转变
第一阶段 重构文件系统和用户空间存储操作系统。实现了毫秒级 P999 延迟。
- 在文件系统关键组件上提出新的设计
- 统一的、附加只写的持久层
- 自包含的块布局
- 设计用户空间存储操作系统 user-space storage operating system (USSOS)
- run-to-completion[1] 线程模型
- 用户空间的资源调度机制:高效分配 CPU 和内存资源
- 部署了在动态环境中提供服务水平协议(SLA)保证的机制
第二阶段 为了适应以性能为导向的商业模式,而进行基础设施的更新和突破网络、内存、CPU的瓶颈。沿着 Cros[2] 拓扑增加服务器和交换机不划算,因此,Pangu 开发了高容量存储服务器(96TB SSD)以及升级网络带宽(100 Gbps)。
- 优化网络带宽:通过减少网络流量放大比例和动态调整不同流量的优先级来优化网络带宽。
- 解决内存瓶颈:提出了远程直接缓存访问(RDCA)来解决内存瓶颈。
- 解决CPU瓶颈:通过消除数据序列化/反序列化的数据税,并引入CPU等待指令来同步超线程来解决CPU瓶颈。
盘古2.0经历了两个阶段的发展,成功从提供100微秒级I/O延迟和1M IOPS的高性能弹性SSD存储服务,到通过基础设施升级和瓶颈突破,实现每台存储服务器的有效吞吐量提升6.1倍,以适应业务从容量导向到性能导向的转变。
Background
Pangu overview
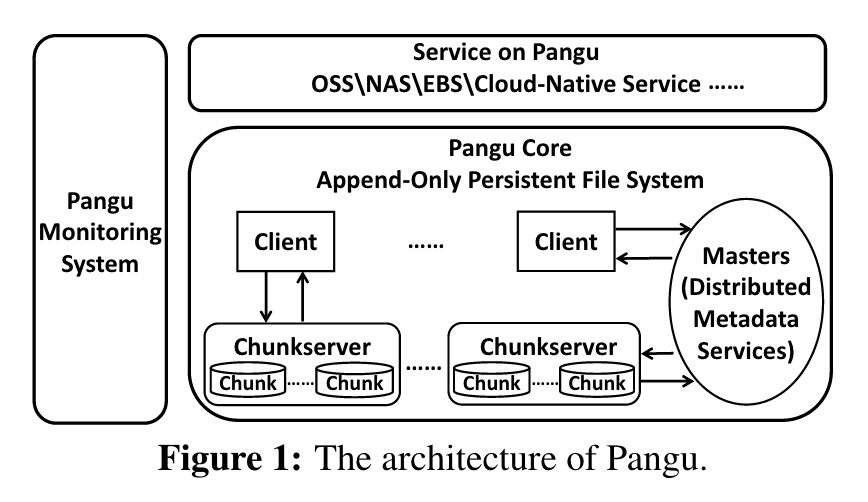
盘古是一个大规模的分布式存储系统,由盘古核心(Pangu Core)、盘古服务(Pangu Service)和盘古监控系统(Pangu Monitoring System)三部分组成。盘古核心包括客户端、主控定点(masters)和数据块服务器(chunkservers),提供了追加只写(append-only)的持久性语义。客户端为盘古云存储服务(例如EBS和OSS)提供SDK,负责接收这些服务的文件请求,并与主控定点和数据块服务器通讯以满足这些请求。与其他分布式文件系统(例如Tectonic和Colossus)相类似,盘古中的客户端是重量级的,并在复制管理、服务水平协议(SLA)保证以及数据一致性管理方面发挥关键作用。
盘古的 Master 管理盘古所有的元数据,使用基于 Raft[3] 的协议来维护元数据的一致性。Master 元数据服务分为 namespace service 和 stream mata service 两部分,负载均衡通过目录树和哈希两层分区实现。namespace service 提供关于文件的信息(例如目录树和命名空间),stream meta service 提供文件到块的映射。Chunkserver 以块的形式存储数据,并配备了定制的用户空间存储文件系统(USSFS),其为不同的硬件提供高性能的 append-only 存储引擎。在盘古2.0第一阶段,每个文件存储了三副本,后来配备了 GC worker 回收并使用纠删码(Ensure Code)来存储文件。在盘古 2.0 第二阶段在关键业务逐渐用 EC 来替代三副本模式来减少盘古的流量放大。
盘古存储系统结合了高性能的核心架构、多样化的云存储服务及先进的实时监控与AI分析,通过高速网络实现模块间互联,为现代云环境提供了强大的数据存储。
Pangu goal
盘古2.0旨在适应硬件技术的新兴和商业模型的转变,致力于实现低延迟、高吞吐量,并为所有服务(如在线搜索、数据流分析、EBS、OSS和数据库)提供统一的高性能支持。
Phase One: Embracing SSD and RDMA
Append-only file system
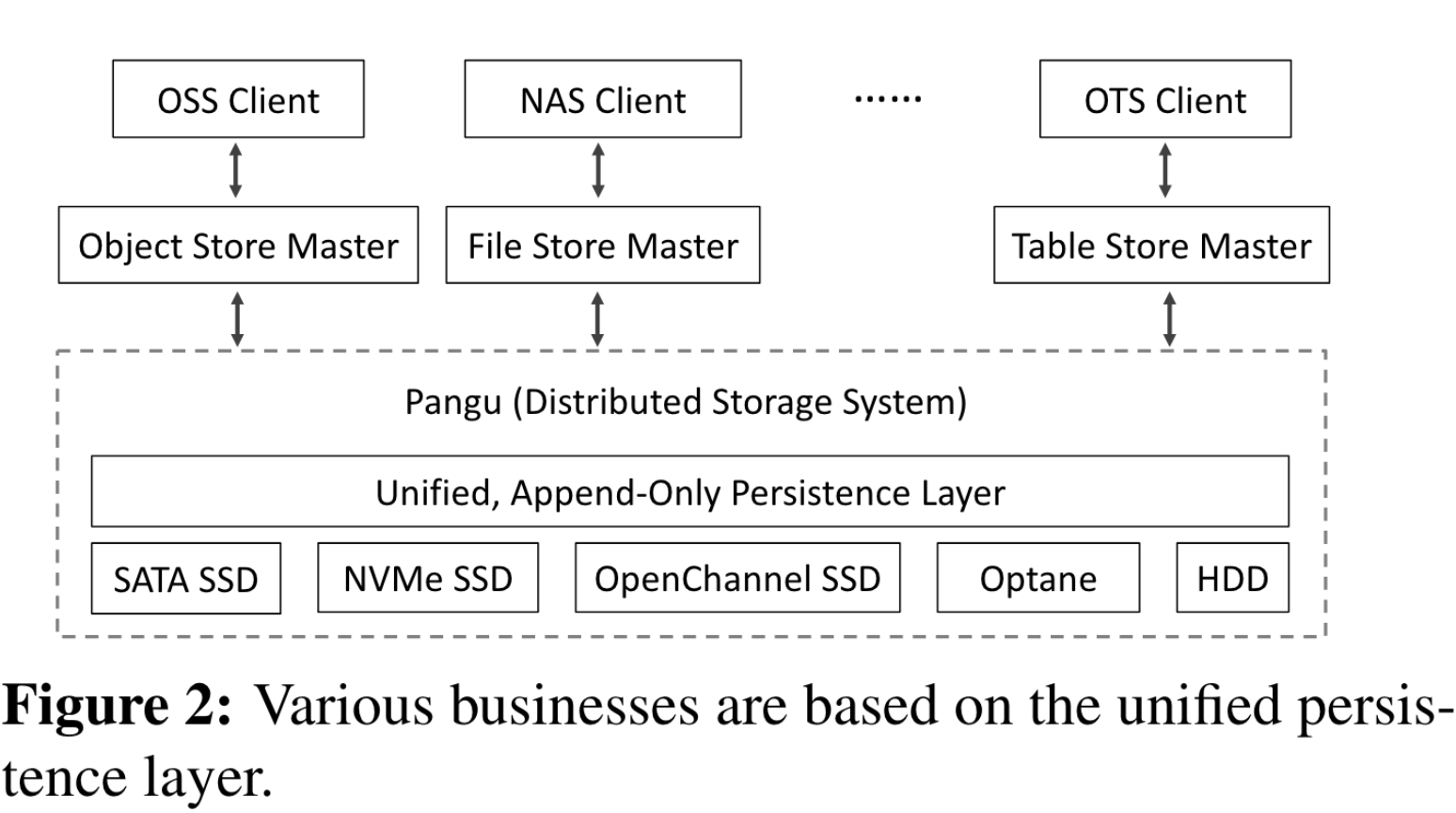
统一的仅追加持久层 盘古为所有存储服务提供接口,在早期开发中,为不同存储服务提供不同接口,这种设计带来了大量开发和管理的复杂性。于是引入了下图中 FlatLogFile 的统一文件类型,具有仅追加语义。
重量级客户端 盘古客户端是重量级的。它负责 chunkserver 的数据操作和元数据服务的操作;负责相应的复制协议和 EC 协议;配备了重试机制;配备了探测机制(探测服务器状态);可以写入或读取不同参数以满足存储服务特定需求。
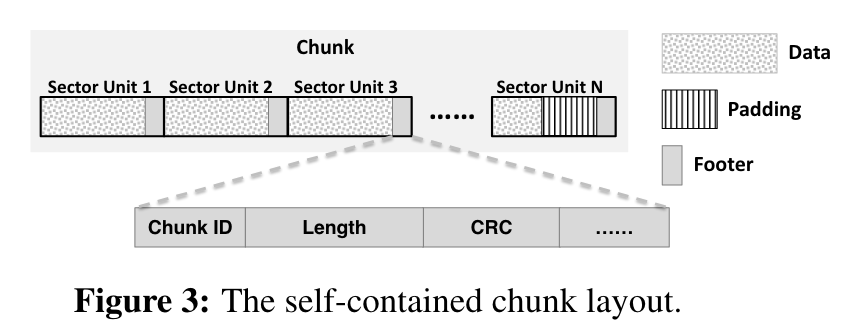
仅追加 Chunk 管理 为了避免传统文件系统如 Ext4 文件数据与元数据分离带来的 SSD 两次的读写,设计了一个如下图所示的自包含块。自包含块还允许故障恢复,具体来说,当 server 连续收到多个写请求,会将写请求的元数据副本存储,定期将这些检查点持久化。当故障发生时,会读取检查点的元数据与存储器中元数据对比,通过 CRC 等进行数据恢复。
元数据操作优化 盘古 master 服务分为名字空间服务(维护目录树和文件管理)和流服务(负责块信息,流为一组块的抽象)。
- 并行元数据处理:使用哈希算法将高度内聚的元数据映射到不同服务器。还使用了一种新的数据结构,支持可预测的目录id[4],并允许客户端高效地并行执行路径解析。
- 长度可变的大块,具有三个好处:
- 减少元数据数量:使用大数据块意味着相对较少的数据块实例,从而减少了需要管理的元数据数量。
- 降低I/O延迟:大数据块减少了客户端频繁请求数据块的情况,有助于避免因多次请求而造成的I/O延迟。
- 提高SSD寿命:大数据块可减少对SSD的写入次数,因为大量小写操作可能更频繁地触发SSD的穿戴平衡机制,从而有效延长SSD的寿命。
- 客户端元数据缓存池
- 推测性块信息预取
- 数据搭载减少一个 RTT
Chunkserver USSOS
用户级别的内存管理
- 运行到完成线程模型,减少上下文切换、线程同步和通信开销
- 线程请求巨页空间作为网络和存储栈的共享内存,实现网络和存储栈的零拷贝
用户空间调度机制
- 为了防止某一个任务占用过多资源而阻塞随后的任务:每个 Chunkserver 都有固定数量的工作线程,对于耗时重的任务,盘古引入了心跳机制来监控任务的执行时间并设置警报,如果任务超过了时间片,将被放入后台线程,从而将其从关键路径中移除;对于系统开销,盘古使用 TCMalloc[5] 缓存,允许高频操作在缓存中完成。
- 为了保证高服务质量(QoS):USSOS创建了优先级队列。然后,任务可以根据它们的QoS目标被放入对应的优先级队列中。
- 轮询和事件驱动交换(NAPI):NIC 提供由应用程序监控的 fd,通过 fd 事件通知应用程序数据到达,默认情况下应用处于事件驱动模式,当收到 NIC 的通知时进入轮询模式。
仅追加的 USSFS 采用了FlatLogFile的追加只写语义,支持追加写操作,并提供了一组基于数据块的语义,例如打开(open)、关闭(close)、封存(seal)、格式化(format)、读取(read)和追加(append),而不是像Ext4那样的标准POSIX语义。
- 充分利用自包含的数据块布局
- 文件系统中不建立层级关系,挂载文件系统通过回放日志重建相应元数据
- 使用轮询模式而不是中断模式
High Performance SLA Guarantee
Chasing 追加确认机制 旨在减少系统抖动对写入延迟的影响。
- 当写入要求
[minCopy, maxCopy], 2 * minCopy > maxCopy,若已写入minCopy个副本块,客户端可向应用程序返回成功。 - 等待时间
t,若所有未完成的副本块都写入完成,则客户端释放数据块。 - 若等待时间还未完成,则针对数据块写入完成情况,完成度低
<k则请求重试,完成度高则封存原有数据块,剩余部分请求从已有的 chunckserver 中复制。
Non-stop Write “不停止写入”机制旨在减少写入操作在某个数据块写失败时的延迟。当发生失败时,客户端会封存该数据块并向主控定点报告成功写入的数据长度。然后,客户端使用一个新的数据块继续写入未完成的数据。
Backup read 在收到先前发送的读请求之前,会向其它 chunckserver 发送额外的读取请求作为备份。盘古计算了不同磁盘类型和 I/O 延迟,根据这个信息动态调整发送备份读请求的时机,同时限制了备份读请求的数量。
Blacklisting 机制 为了避免向服务质量差的 chunckserver 发送请求,引入了永久黑名单和临时黑名单的方式。
- 对于确定的某个 chunckserver 不可用(如 SSD 损坏),加入永久黑名单
- 对于延迟超过某个阈值,添加限时黑名单中,客户端周期性发送 I/O 探测决定解禁
Phase Two: Adapting to PerformanceOriented Business Model
自2018年以来,盘古逐渐从以容量为导向的存储提供商转变为以性能为导向的提供商。因此,盘古开发了自家的存储服务器泰山。一个泰山服务器配备了2×24核心的Skylake CPU、12×8TB的商用SSD、128GB DDR内存和2×双端口100Gbps的网络接口卡(NIC)。新硬件在大规模部署中也会带来新的技术挑战。为此,我们提出并部署了一系列新颖的技术来优化盘古海量网络、内存和CPU资源的运行。
Network Bottleneck
带宽扩展 硬件升级,软件改进。为了避免 RDMA 暂停帧带来的流控制问题(死锁、行首阻塞),盘古升级到有损的RDMA,即禁用暂停帧,以避免这些问题并提高性能。
交通优化
- EC 纠删码替代三副本方案
- LZ4 算法压缩
FlatLogFile - 前台流量和后台流量带宽动态分配:如 GC 等后台流量在闲时设置更高
Memory Bottleneck
盘古的基本内存瓶颈在于接收器主机网络进程和应用程序进程的内存带宽争用。
增加小容量 DRAM 充分利用内存通道 由于瓶颈在于内存带宽而不是内存容量,因此我们在服务器中增加了更多容量较小的DRAM(例如,16GB)来充分利用内存通道,并增加每台服务器可用的内存带宽。我们还启用了非一致性存储访问(NUMA)配置,以避免跨插槽的内存访问受到超路径互连(Ultra Path Interconnect)的限制。
后台流量用 RDMA 传输 随着网络升级,盘古开始使用 RDMA 传输后台流量
RDCA 为了增加可用的内存带宽和减少不必要的内存带宽消耗,提出了远程直接缓存访问(RDCA)架构。
- Cache-resident buffer pool:缓存驻留缓冲池。该池使用共享接收器队列(SRQ)来接收小消息,并使用配备有基于窗口的速率控制机制的读取缓冲器来接收大消息,使得RDMA操作所需的存储器缓冲器能够适合高速缓存。
- 快速缓存回收:为了以尽可能少的LLC(Last Level Cache)支持以高速率运行的100 Gbps NIC,我们设计了swift缓存回收机制,通过(1)沿流水线并行处理数据,以及(2)使用硬件卸载和轻量级(反)序列化优化处理来减少数据的后NIC时间跨度。
- “缓存压力感知逃逸机制”是为应对偶发的系统抖动设计的,比如SSD写入缓慢或应用程序异常。该机制监控保留的LLC(Last Level Cache,末级缓存)的使用情况,并采取相应的措施:
- 替换滞后数据缓冲区:通过添加新的缓冲区到常驻缓存缓冲池,替换滞后数据的缓存缓冲区,以使得RDCA(Remote Direct Memory Access, 远程直接内存访问缓存感知)中可用缓存的大小不因新到来请求而变化。
- 主动内存复制:如果发生了太多的缓存替换,主动将慢速运行应用程序的数据复制到内存,以便其他应用程序可以使用RDCA缓冲池,且该池不会占用过多缓存。
- 显式拥塞通知:如果复制到内存失败或在释放缓存压力方面不足,让网络接口卡(NIC)在拥塞通知数据包中标记显式拥塞通知(ECN)以指示拥塞。
CPU Bottleneck
Hybrid RPCs Protobuf 序列化和反序列化大概需要 30% CPU 开销。
- 对于数据路径,采用 FlatBuffer 的原始结构无需序列化
- 对于控制操作,出于灵活性和复杂性考虑,仍然采用 Protobuf
Hyper-Threading 使用超线程技术,为了减轻超线程技术带来的上下文切换、相互影响的问题,盘古引入了 CPU 等待指令 monitor 和 mwait
Hardware and Software Co-design 数据压缩卸载到 FPGA 硬件中,CRC 卸载到 RDMA capable NICs 中。
Lessons
USSOS
- 用户空间系统的简易性:更容易开发和运维
- 借鉴内核空间设计
- 针对不同存储介质的性能提升
performance-cost tradeoff
硬件扩展能有效提升盘古的性能,但成本问题,这种做法不可持续。因此需要在流量优化等多方面努力提高资源利用率和效率。
PM
持久内存有许多优点,如快速数据持久化、适合 RDMA、低读取延迟、低尾延迟和缓存友好性等。因此,盘古在这个基础上开发了 30 微秒的 EBS 服务,然而英特尔停止了 PM 服务,迫使盘古需要重新考虑该服务。在开发新服务时,需要更周全地规划。
hardware offloading
在盘古系统中,硬件卸载的成本效益权衡是一个关键议题。生产过程中解决了FPGA硬件成本、压缩数据的完整性以及与硬件中的其他功能共存的问题。