

Go sync.Map 源码走读
Go1.24 将 sync.Map 即线程安全哈希表从 “双哈希表” 的结构转化成了 HashTrieMap 哈希前缀树的结构,本文是对该代码的走读。
HashTrieMap 实际就是将 Hash(key) 作为并发前缀树的输入进行存储。
简单回顾
HashTrieMap 是哈希和前缀树的结合,涉及到了哈希种子、哈希冲突方法,前缀树的延迟展开技术。
哈希
哈希种子:是一个用于初始化哈希函数计算过程的随机值,其主要作用是引入随机性。目的:通过使用不同的种子,即使输入相同,哈希函数也能产生不同的输出。这主要用于应对哈希碰撞拒绝服务攻击,因为攻击者难以预测特定种子下会产生碰撞的输入
哈希冲突解决方法:
链地址法(拉链法):将哈希到同一地址的所有元素存储在一个链表(或其他数据结构,如红黑树)中。本文的 HashTrieMap 就是链表的拉链法。
开放定址法
当冲突发生时,按照某种探查序列在哈希表中寻找下一个空闲的位置。探查序列的生成方式有多种:
- 线性探测:顺序检查下一个位置,直到找到空槽。容易产生“聚集”现象
- 平方探测:探查序列为原哈希地址加上某个平方数(如 1², -1², 2², -2²...),有助于缓解聚集
- 双散列法:使用第二个哈希函数来计算探测步长,是开放定址法中较好的方法,能产生较好的随机分布
再哈希法:准备多个不同的哈希函数。当第一个哈希函数发生冲突时,尝试使用第二个、第三个哈希函数,直到找到不冲突的位置为止。这种方法增加了计算时间,但可以减少聚集
建立公共溢出区
布谷哈希:借鉴了布谷鸟的“巢寄生”行为:布谷鸟会将蛋产在其他鸟的巢中,并将原有的鸟蛋推出巢外。在算法中,当插入一个新元素时,如果它预定的两个位置都被占用,便会“踢出”其中一个已存在的元素,而被踢出的元素会去寻找它的另一个备选位置,这个过程可能会连锁进行
前缀树
前缀树直观情况如下图:
- 这里的前缀树节点是 a-z 的字母,如果是二进制表示,则可以是 u4 可以是 u8 也可以是 u16 等
- 这里的前缀树可以表示为无限长度的字符串,如果是有限长度的字符串,那么层数就是有限的

介绍一下自适应基数树(ART)对前缀树的优化之 lazy expansion,HashTrieMap 就使用到了这个技术,简而言之,当 trie 中只有 FOO 时会产生三层节点,但如果惰性展开,就可以有 FOO 一个节点,当出现 FOU 时,才会裂出 F - O - O 和 F - O - U 三层节点。
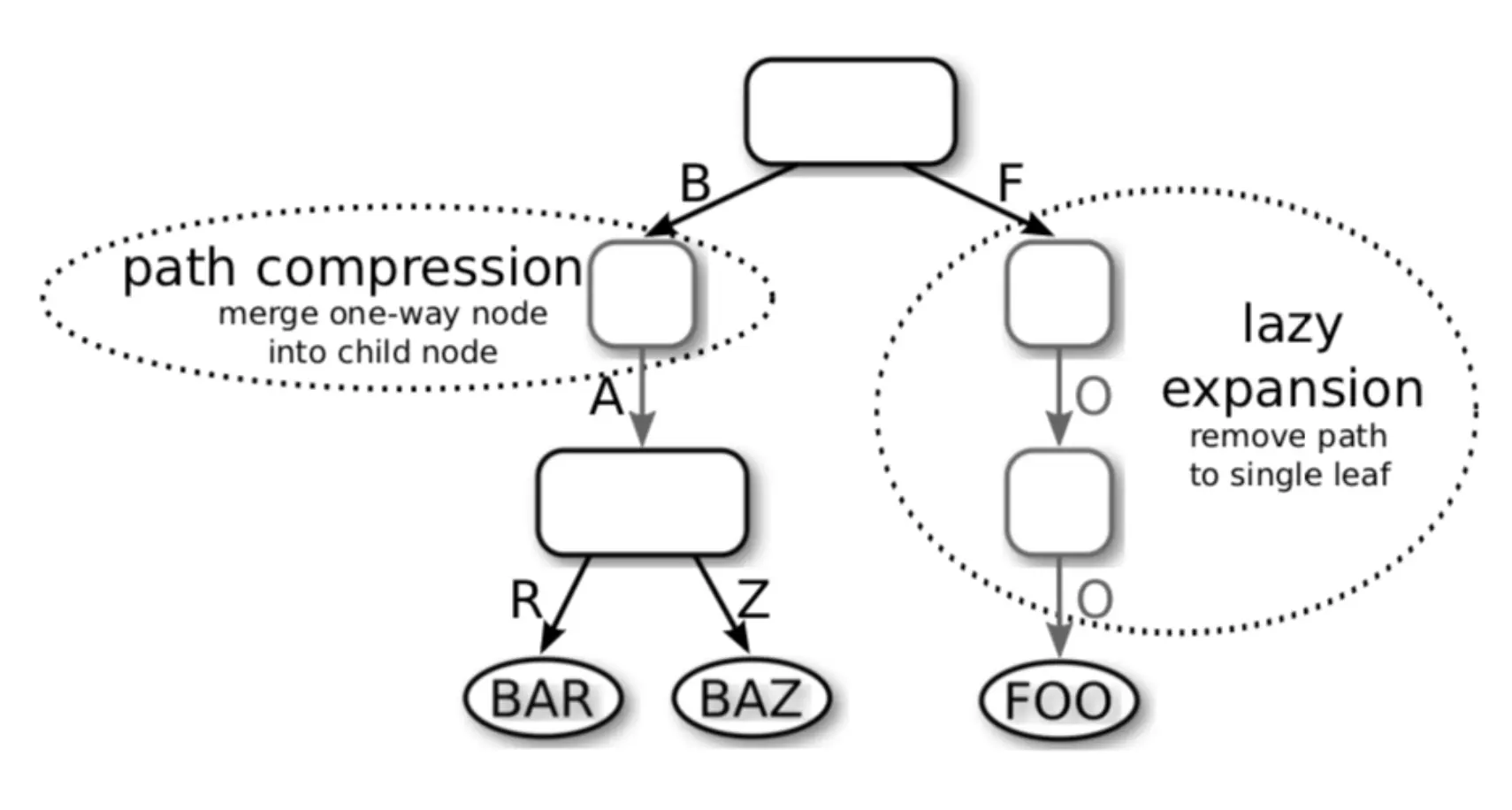
HashTrieMap 实际就是将 key 哈希到一个 u64 然后将 u64 分为 16 段,那么每个前缀的字符就是一个 u4,将这个作为前缀树的输入,该前缀树最多有 16 层。
HashTrieMap 结构体
inited原子标志位,代表是否经过初始化;initMu初始化互斥量root前缀树的根节点keyHash哈希函数;valEqual等值函数;seed哈希种子
// HashTrieMap is an implementation of a concurrent hash-trie. The implementation
// is designed around frequent loads, but offers decent performance for stores
// and deletes as well, especially if the map is larger. Its primary use-case is
// the unique package, but can be used elsewhere as well.
//
// The zero HashTrieMap is empty and ready to use.
// It must not be copied after first use.
type HashTrieMap[K comparable, V any] struct {
inited atomic.Uint32
initMu Mutex
root atomic.Pointer[indirect[K, V]]
keyHash hashFunc
valEqual equalFunc
seed uintptr
}init 初始化
HashTrieMap 采用 LazyInit 的方式进行初始化,即当访问到其中方法时进行初始化。
init标志位为 0 时,进行实际初始化- 实际初始化时,加锁初始化
root和哈希函数有关的变量
func (ht *HashTrieMap[K, V]) init() {
if ht.inited.Load() == 0 {
ht.initSlow()
}
}
//go:noinline
func (ht *HashTrieMap[K, V]) initSlow() {
ht.initMu.Lock()
defer ht.initMu.Unlock()
if ht.inited.Load() != 0 {
// Someone got to it while we were waiting.
return
}
// Set up root node, derive the hash function for the key, and the
// equal function for the value, if any.
var m map[K]V
mapType := abi.TypeOf(m).MapType()
ht.root.Store(newIndirectNode[K, V](nil))
ht.keyHash = mapType.Hasher
ht.valEqual = mapType.Elem.Equal
ht.seed = uintptr(runtime_rand())
ht.inited.Store(1)
}前缀树节点
首先了解一下前缀树的具体节点结构:
indirect节点:node[K, V]节点 header,用以确定是否是 entry 节点dead墓碑标志,标志是否被删除mu节点互斥量parent父节点指针children一个固定的数组,存储子节点的header,即当子节点为 nil 时,只占用 header 的空间
entry节点:node[K, V]节点 header,用以确定是否是 entry 节点overflow溢出节点,很明显,这里处理哈希冲突的方式是链式key, value具体类型
// node is the header for a node. It's polymorphic and
// is actually either an entry or an indirect.
type node[K comparable, V any] struct {
isEntry bool
}
// indirect is an internal node in the hash-trie.
type indirect[K comparable, V any] struct {
node[K, V]
dead atomic.Bool
mu Mutex // Protects mutation to children and any children that are entry nodes.
parent *indirect[K, V]
children [nChildren]atomic.Pointer[node[K, V]]
}
// entry is a leaf node in the hash-trie.
type entry[K comparable, V any] struct {
node[K, V]
overflow atomic.Pointer[entry[K, V]] // Overflow for hash collisions.
key K
value V
}HashTrieMap 各方法
下面进行阅读 TrieMap 是如何尽可能地使用无锁操作来加速并发操作的。主要集中在 Store/Load/LoadAndDelete 函数中。
Store
通过调用链路,可以发现,增/改操作集中在 Swap 函数中
// Store sets the value for a key.
func (ht *HashTrieMap[K, V]) Store(key K, old V) {
_, _ = ht.Swap(key, old)
}Swap 函数具体流程:
- (如有)惰性初始化
- 计算哈希值 hash 作为 Trie 的输入
- 将 hash 分为若干段,每段就是前缀树的一个字符
- 通过 CAS 无锁找到前缀树的插入位置并加锁、校验:此时已经获得了底层锁的节点和槽位
- 如果 KV 对已存在或槽位为空,则可直接更改或插入
- 如果 KV 对不存在且槽位已经有值了,则需要进行 expand 扩展操作
- 如果哈希碰撞,则直接赋值为溢出节点
- 否则逐层增加 indirect 节点,直到能够区分 oldEntry 和 newEntry
// Swap swaps the value for a key and returns the previous value if any.
// The loaded result reports whether the key was present.
func (ht *HashTrieMap[K, V]) Swap(key K, new V) (previous V, loaded bool) {
// 惰性初始化
ht.init()
// 计算哈希值
hash := ht.keyHash(abi.NoEscape(unsafe.Pointer(&key)), ht.seed)
// 遍历的节点指针
var i *indirect[K, V]
var hashShift uint // 用以取出 hash 值的某个部分,也就是前缀树中的‘字符’
var slot *atomic.Pointer[node[K, V]]
var n *node[K, V]
for {
// 找到 key 所在位置 或者是 插入位置
// Find the key or a candidate location for insertion.
// 从根节点遍历
i = ht.root.Load()
hashShift = 8 * goarch.PtrSize // 初始化为 hash 的全 bits 数量
haveInsertPoint := false
for hashShift != 0 { // 每 shift 一次是一层
hashShift -= nChildrenLog2
slot = &i.children[(hash>>hashShift)&nChildrenMask] // 定位到该层的指定位置
n = slot.Load()
// 如果槽位为空 或者说 槽位是 kv 对,则说明 n 就是所要插入的位置
if n == nil || n.isEntry {
// We found a nil slot which is a candidate for insertion,
// or an existing entry that we'll replace.
haveInsertPoint = true
break
}
// 否则到下一层节点
i = n.indirect()
}
// 最深的层级就是固定的层数,一定能找到插入点
if !haveInsertPoint {
panic("internal/sync.HashTrieMap: ran out of hash bits while iterating")
}
// 以上完成对插入/更新位置的无锁搜索
// 以下正式对该位置进行加锁:
// Grab the lock and double-check what we saw.
i.mu.Lock()
n = slot.Load()
// 由于搜索过程是无锁的,所以需要重新对该位置的条件进行校验,校验通过后才算合格的位置
// 对该位置的锁保留到循环外面
if (n == nil || n.isEntry) && !i.dead.Load() {
// What we saw is still true, so we can continue with the insert.
break
}
// We have to start over.
i.mu.Unlock()
}
// N.B. This lock is held from when we broke out of the outer loop above.
// We specifically break this out so that we can use defer here safely.
// One option is to break this out into a new function instead, but
// there's so much local iteration state used below that this turns out
// to be cleaner.
defer i.mu.Unlock()
var zero V
var oldEntry *entry[K, V]
// 如果 entry 中存在 key,进行 V 的更新,即 Update
if n != nil {
// Swap if the keys compare.
oldEntry = n.entry()
newEntry, old, swapped := oldEntry.swap(key, new)
if swapped {
slot.Store(&newEntry.node)
return old, true
}
}
// 如果不存在,则进行 <k, v> 的插入
// The keys didn't compare, so we're doing an insertion.
newEntry := newEntryNode(key, new)
if oldEntry == nil {
// 如果空槽,直接插入
// Easy case: create a new entry and store it.
slot.Store(&newEntry.node)
} else {
// 否则需要 expand,即向下扩展
// We possibly need to expand the entry already there into one or more new nodes.
//
// Publish the node last, which will make both oldEntry and newEntry visible. We
// don't want readers to be able to observe that oldEntry isn't in the tree.
slot.Store(ht.expand(oldEntry, newEntry, hash, hashShift, i))
}
return zero, false
}
// expand takes oldEntry and newEntry whose hashes conflict from bit 64 down to hashShift and
// produces a subtree of indirect nodes to hold the two new entries.
func (ht *HashTrieMap[K, V]) expand(oldEntry, newEntry *entry[K, V], newHash uintptr, hashShift uint, parent *indirect[K, V]) *node[K, V] {
// Check for a hash collision.
// 如果是哈希碰撞,直接将老 entry 作为溢出节点后继
oldHash := ht.keyHash(unsafe.Pointer(&oldEntry.key), ht.seed)
if oldHash == newHash {
// Store the old entry in the new entry's overflow list, then store
// the new entry.
newEntry.overflow.Store(oldEntry)
return &newEntry.node
}
// 否则增加 indirect 节点,直到能够区分 oldEntry 和 newEntry
// We have to add an indirect node. Worse still, we may need to add more than one.
newIndirect := newIndirectNode(parent)
top := newIndirect
for {
if hashShift == 0 {
panic("internal/sync.HashTrieMap: ran out of hash bits while inserting")
}
hashShift -= nChildrenLog2 // hashShift is for the level parent is at. We need to go deeper.
oi := (oldHash >> hashShift) & nChildrenMask
ni := (newHash >> hashShift) & nChildrenMask
// 可以区分,作为 IndirectNode 的两个 Slot
if oi != ni {
newIndirect.children[oi].Store(&oldEntry.node)
newIndirect.children[ni].Store(&newEntry.node)
break
}
// 不能区分,新增一级
nextIndirect := newIndirectNode(newIndirect)
newIndirect.children[oi].Store(&nextIndirect.node)
newIndirect = nextIndirect
}
return &top.node
}Load
- (如有)惰性初始化
- 计算哈希值 hash 作为 Trie 的输入
- 将 hash 分为若干段,每段就是前缀树的一个字符
- 通过 CAS 无锁找到前缀树的 Slot 返回结果
// Load returns the value stored in the map for a key, or nil if no
// value is present.
// The ok result indicates whether value was found in the map.
func (ht *HashTrieMap[K, V]) Load(key K) (value V, ok bool) {
// 惰性初始化
ht.init()
// 哈希计算
hash := ht.keyHash(abi.NoEscape(unsafe.Pointer(&key)), ht.seed)
// 无锁 CAS 定位
i := ht.root.Load()
hashShift := 8 * goarch.PtrSize
for hashShift != 0 {
hashShift -= nChildrenLog2
n := i.children[(hash>>hashShift)&nChildrenMask].Load()
if n == nil {
return *new(V), false
}
if n.isEntry {
return n.entry().lookup(key)
}
i = n.indirect()
}
panic("internal/sync.HashTrieMap: ran out of hash bits while iterating")
}LoadAndDelete
(如有)惰性初始化
计算哈希值 hash 作为 Trie 的输入
将 hash 分为若干段,每段就是前缀树的一个字符
使用 finde 方法找到 k 对应的槽位并加锁
如果无锁搜索过程中发现没有 Slot,返回不存在
定位到 Slot 后,加锁校验值的有效性并返回,有效则需要调用方进行解锁
对定位到的 Slot 进行删除
如果删除后中间节点变为空节点,则需要递归向上删除:
- 将父节点指针置为空
- 将自身做死亡标记
// LoadAndDelete deletes the value for a key, returning the previous value if any.
// The loaded result reports whether the key was present.
func (ht *HashTrieMap[K, V]) LoadAndDelete(key K) (value V, loaded bool) {
// 惰性初始化
ht.init()
// 计算哈希值
hash := ht.keyHash(abi.NoEscape(unsafe.Pointer(&key)), ht.seed)
// Find a node with the key and compare with it. n != nil if we found the node.
// 找到 k 对应的槽位并加锁
i, hashShift, slot, n := ht.find(key, hash, nil, *new(V))
if n == nil {
if i != nil {
i.mu.Unlock()
}
return *new(V), false
}
// Try to delete the entry.
// 对槽位进行删除
v, e, loaded := n.entry().loadAndDelete(key)
if !loaded {
// Nothing was actually deleted, which means the node is no longer there.
i.mu.Unlock()
return *new(V), false
}
if e != nil {
// We didn't actually delete the whole entry, just one entry in the chain.
// Nothing else to do, since the parent is definitely not empty.
slot.Store(&e.node)
i.mu.Unlock()
return v, true
}
// Delete the entry.
slot.Store(nil)
// Check if the node is now empty (and isn't the root), and delete it if able.
// 如果中间节点被删除后为空节点
// 则需要递归删除父节点中的指针,并将自己做死亡标记
for i.parent != nil && i.empty() {
if hashShift == 8*goarch.PtrSize {
panic("internal/sync.HashTrieMap: ran out of hash bits while iterating")
}
hashShift += nChildrenLog2
// Delete the current node in the parent.
parent := i.parent
parent.mu.Lock()
i.dead.Store(true)
parent.children[(hash>>hashShift)&nChildrenMask].Store(nil)
i.mu.Unlock()
i = parent
}
i.mu.Unlock()
return v, true
}
// find searches the tree for a node that contains key (hash must be the hash of key).
// If valEqual != nil, then it will also enforce that the values are equal as well.
//
// Returns a non-nil node, which will always be an entry, if found.
//
// If i != nil then i.mu is locked, and it is the caller's responsibility to unlock it.
func (ht *HashTrieMap[K, V]) find(key K, hash uintptr, valEqual equalFunc, value V) (i *indirect[K, V], hashShift uint, slot *atomic.Pointer[node[K, V]], n *node[K, V]) {
for {
// 无锁定位到指定 Slot
// 如果没有则可直接返回
// Find the key or return if it's not there.
i = ht.root.Load()
hashShift = 8 * goarch.PtrSize
found := false
for hashShift != 0 {
hashShift -= nChildrenLog2
slot = &i.children[(hash>>hashShift)&nChildrenMask]
n = slot.Load()
if n == nil {
// Nothing to compare with. Give up.
i = nil
return
}
if n.isEntry {
// We found an entry. Check if it matches.
if _, ok := n.entry().lookupWithValue(key, value, valEqual); !ok {
// No match, comparison failed.
i = nil
n = nil
return
}
// We've got a match. Prepare to perform an operation on the key.
found = true
break
}
i = n.indirect()
}
if !found {
panic("internal/sync.HashTrieMap: ran out of hash bits while iterating")
}
// 定位到指定 Slot 后,加锁校验,防止在无锁定位过程中被删除
// Grab the lock and double-check what we saw.
i.mu.Lock()
n = slot.Load()
if !i.dead.Load() && (n == nil || n.isEntry) {
// Either we've got a valid node or the node is now nil under the lock.
// In either case, we're done here.
return
}
// We have to start over.
i.mu.Unlock()
}
}总结
总结一下 HashTrieMap 快的原因:
- 路径搜索是无锁 CAS 的,到尾节点才会加锁,大大降低了锁的粒度
- 使用到了类似 ART 的延迟展开技术,动态减小 Trie 的层数